JSON 计算
工作流:JSON 计算社区版+介绍
基于不同的 JSON 计算引擎,对上游节点产生的复杂 JSON 数据进行计算或结构变换,以便后续节点使用。例如 SQL 操作和 HTTP 请求节点的结果,可以通过该节点将其变换为需要的值和变量格式,以便后续节点使用。
创建节点
在工作流配置界面中,点击流程中的加号(“+”)按钮,添加“JSON 计算”节点:
通常会将 JSON 计算节点创建在其他数据节点的下方,以便对其进行解析。
节点配置
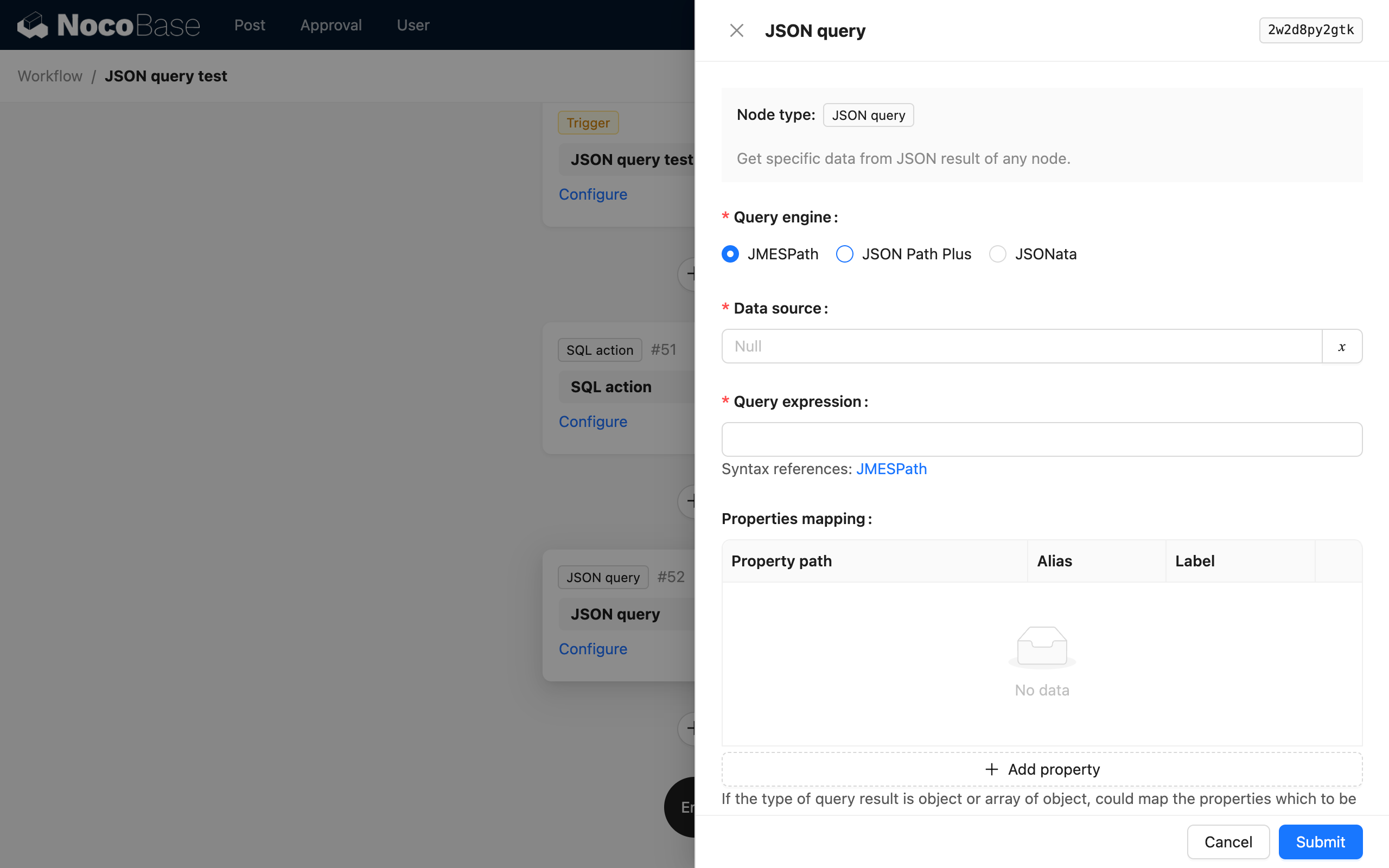
解析引擎
JSON 计算节点通过不同的解析引擎来支持不同的语法,可以根据自己的偏好和各个引擎的特色来进行选择。目前支持三种解析引擎:
数据源
数据源可以是上游节点的结果,也可以是流程上下文中的数据对象,通常是一个没有内置结构化的数据对象,例如 SQL 节点的结果,或者 HTTP 请求节点的结果。
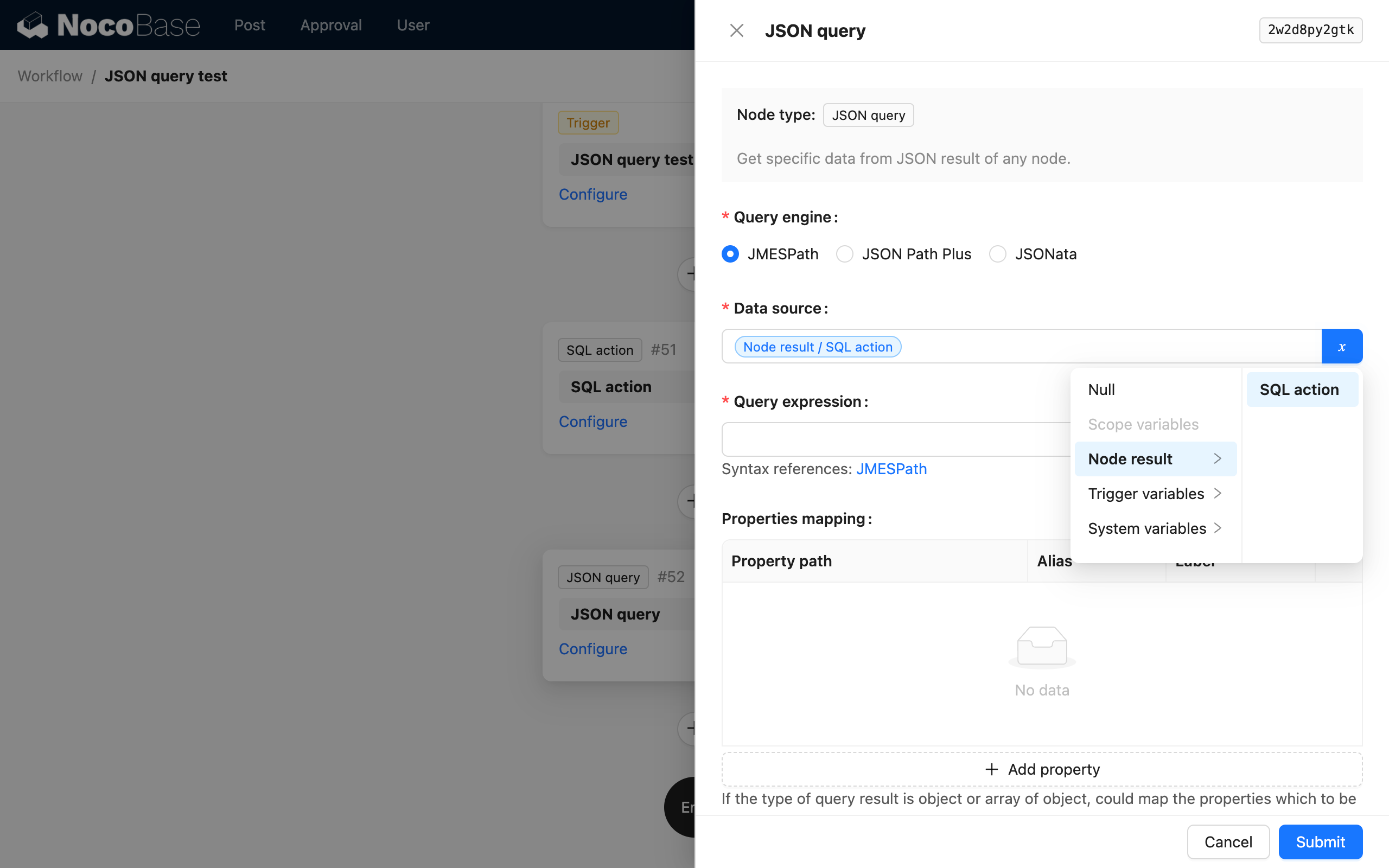
通常数据表相关节点的数据对象都是通过数据表配置信息结构化过的,一般不需要通过 JSON 计算节点进行解析。
解析表达式
基于解析需求和解析引擎的不同,自定义的解析表达式。
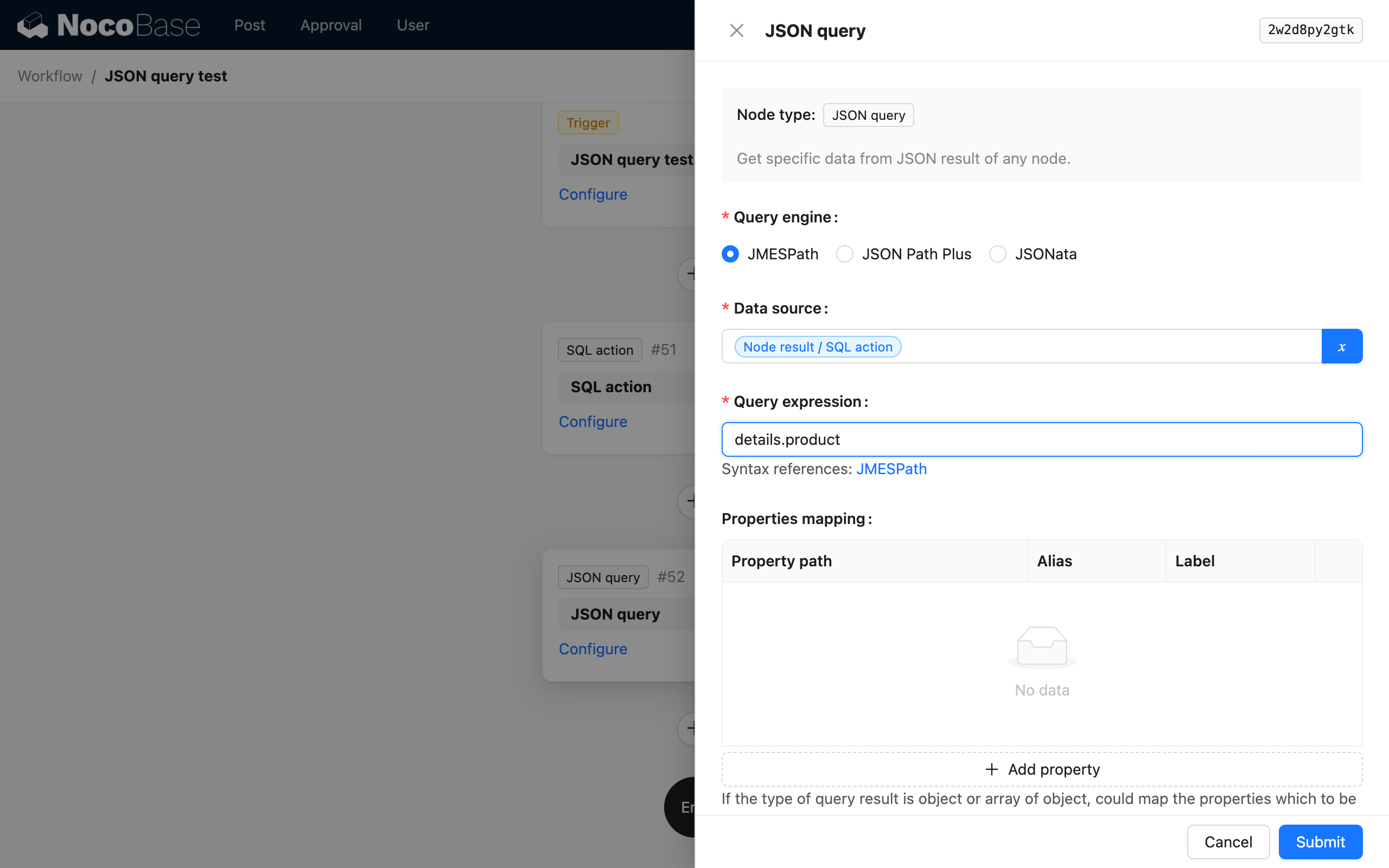
不同引擎提供不同的解析语法,具体可以查阅链接中的文档。
自 v1.0.0-alpha.15 版本起,表达式支持使用变量,变量会在具体的引擎执行前进行预解析,按照字符串模板的规则将变量替换为具体的字符串值,并与表达式的其他静态字符串拼接为最终的表达式。这个功能在需要动态构建表达式时非常有用,例如某些 JSON 内容需要动态 key 来解析的时候。
属性映射
当计算的结果是一个对象(或对象数组)时,可以通过属性映射进一步将所需要的属性映射为子级变量,以供后续节点使用。
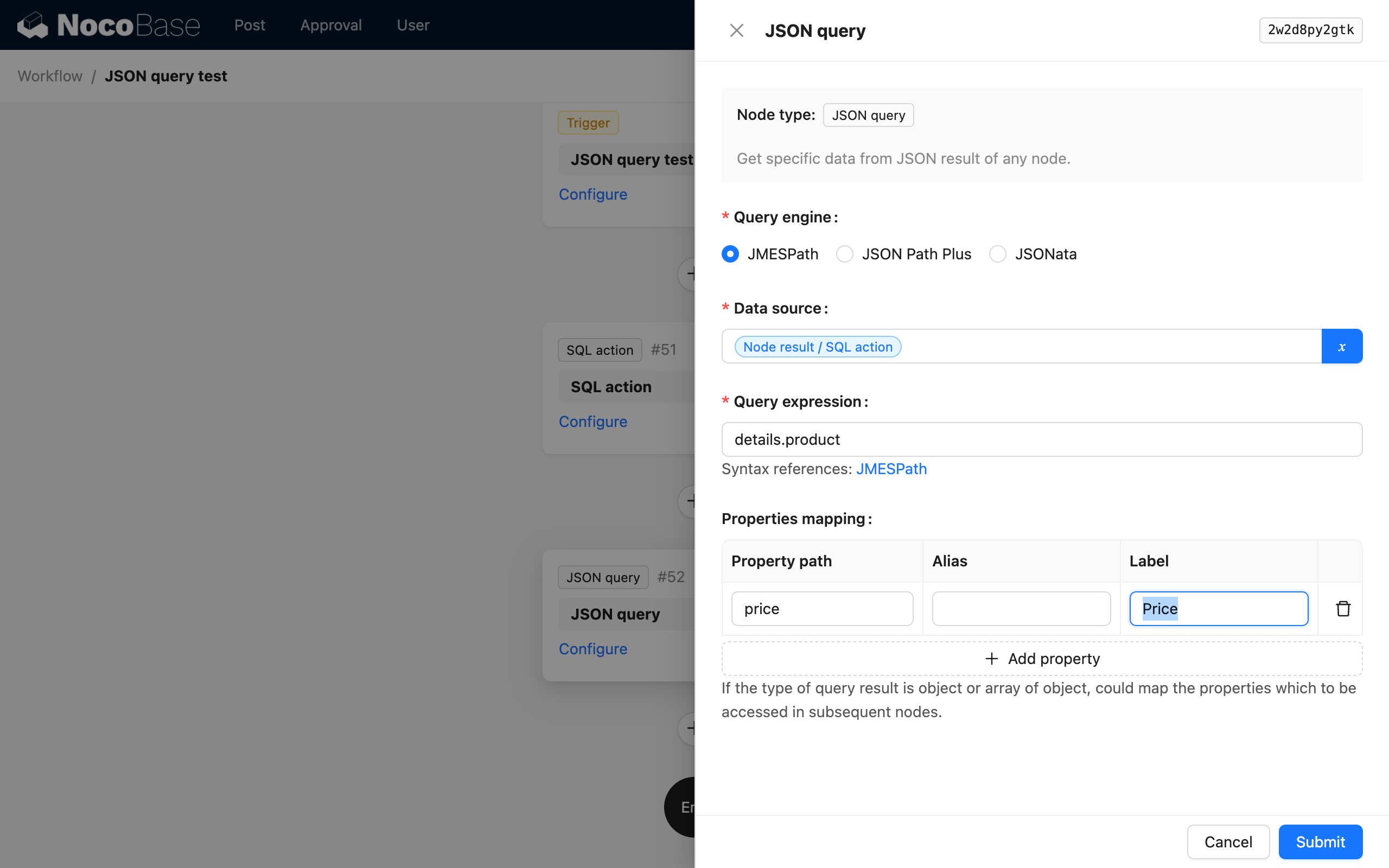
对于对象(或对象数组)结果,如果不进行属性映射,则会将整个对象(或对象数组)作为一个变量保存在节点的结果中,无法以变量的方式直接使用对象的属性值。
示例
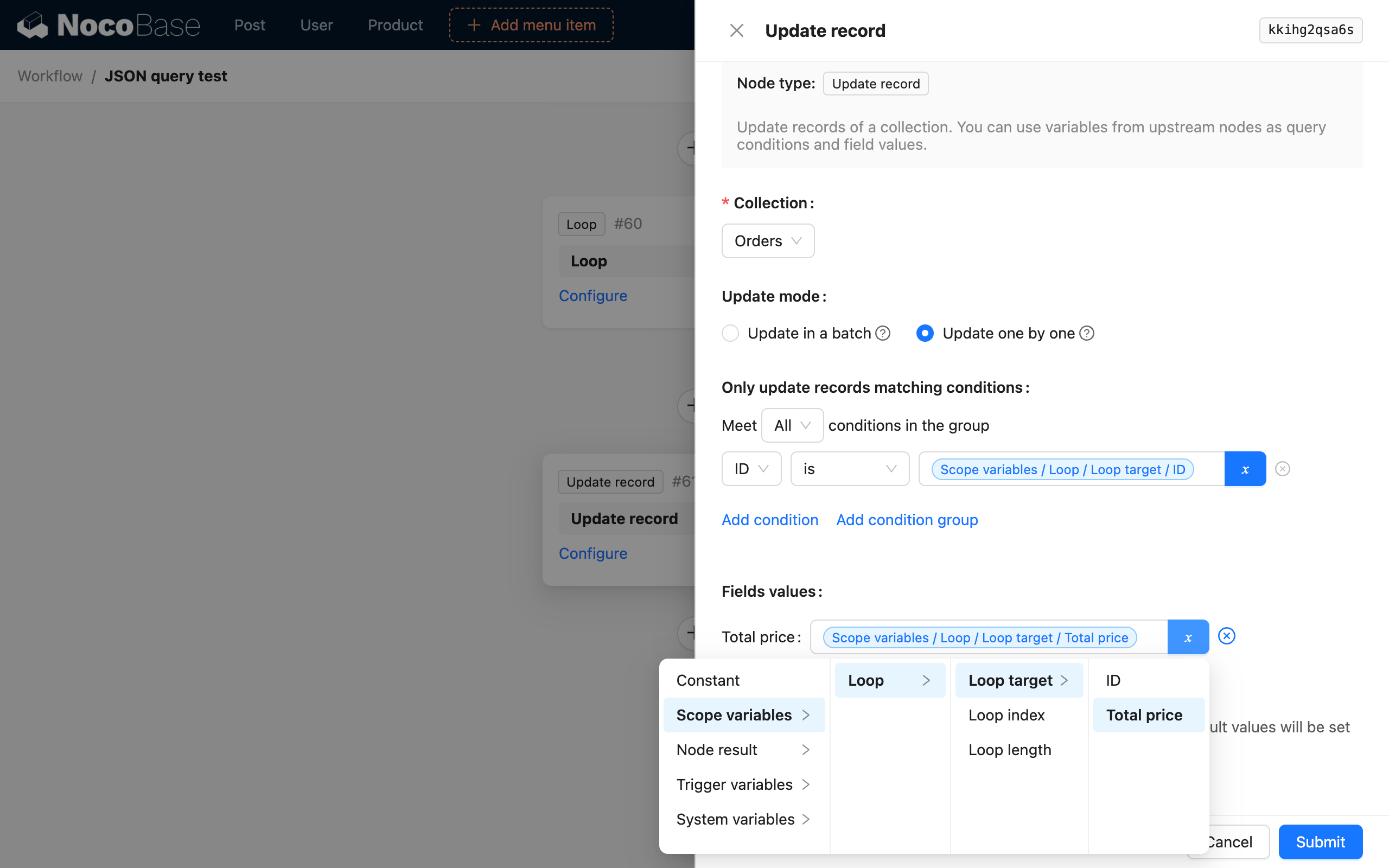
假设需要解析的数据是前序的 SQL 节点用于查询数据,其结果为一组订单数据:
如果我们需要解析并计算出数据中两个订单分别的总价,并和对应的订单 ID 组装成对象,用于更新订单总价,可以按下面的配置:
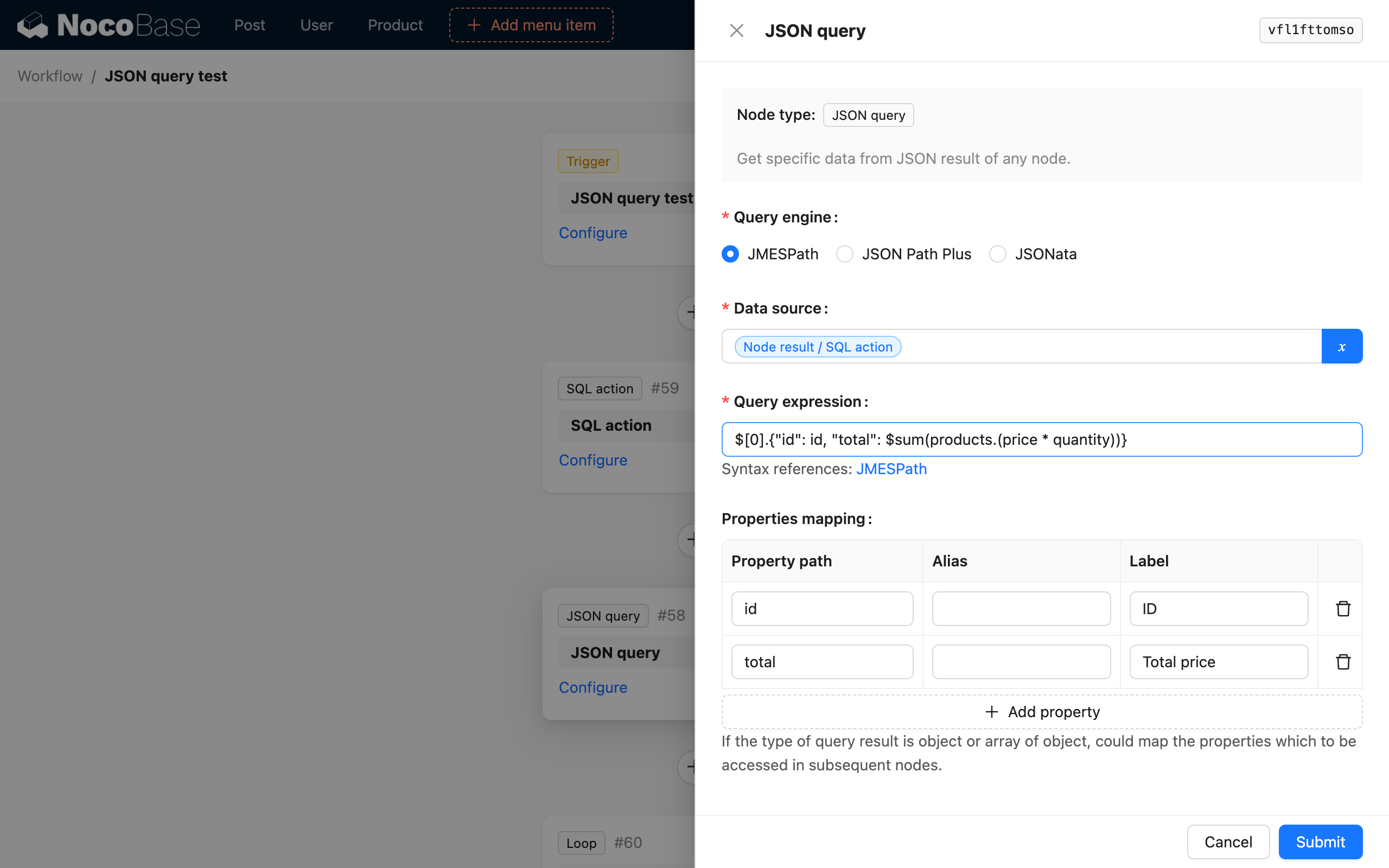
- 选择 JSONata 解析引擎;
- 选择 SQL 节点的结果作为数据源;
- 使用 JSONata 表达式
$[0].{"id": id, "total": products.(price * quantity)}解析; - 选择属性映射,将
id和total映射为子级变量;
最终的解析结果如下:
之后再循环取值完成的订单数组,更新��订单的总价即可。