

扩展节点类型
节点的类型本质上就是操作指令,不同的指令代表流程中执行的不同的操作。
与触发器类似,扩展节点的类型也分为前后端两部分。服务端需要对注册的指令进行逻辑实现,客户端需要提供指令所在节点相关参数的界面配置。
服务端
最简单的节点指令
指令的核心内容是一个函数,也就是指令类中的 run 方法是必须实现的,用于执行指令的逻辑。函数中可以执行任意需要的操作,例如数据库操作、文件操作、调用第三方 API 等等。
所有指令都需要派生自 Instruction 基类,最简单的指令只需要实现一个 run 函数即可:
并将该指令注册到工作流插件中:
指令的返回对象中的状态值(status)是必填内容,而且必须是常量 JOB_STATUS 中的值,该值将决定该节点在流程中的后续处理的流向。通常使用 JOB_STATUS.RESOVLED 即可,代表该节点成功执行完毕,会继续后续节点的执行。如果有需要提前保存的结果值,也可以调用 processor.saveJob 方法,并返回该方法的返回对象。执行器会根据该对象生成执行结果记录。
节点的结果值
如果有特定的执行结果,尤其是准备可供后续节点使用的数据,可以通过 result 属性返回,并保存在节点任务对象中:
其中 node.config 是节点的配置项,可以是需要的任意值,会以 JSON 类型字段保存在数据库对应的节点记录中。
指令的错误处理
如果执行过程可能会有异常,可以提前捕获后并返回失败状态:
如果不对可预测的异常进行捕获,那么流程引擎会自动捕获并返回出错状态,以避免未捕获的异常造成程序崩溃。
异步节点
当节点需要等待外部操作�完成后才能继续流程时(如 HTTP 请求、第三方支付回调等耗时或非即时返回的操作),应先将任务保存为 JOB_STATUS.PENDING 状态以挂起当前执行,待操作完成后再通过 resume 恢复。凡是使用了挂起逻辑的指令,必须同时实现 resume 方法,否则流程将无法恢复。
推荐的实现模式如下:
这里有几个关键细节说明:
为什么要主动调用 processor.exit() 而不是返回挂起的任务对象?
return { status: PENDING } 会立即结束 run 函数,之后无法再执行任何代码。主动调用 await processor.exit() 则只是提交事务并退出数据库上下文,函数本身仍在继续执行,这样才能在同一函数体内 await 耗时操作,完成后再调用 resume。如果不先调用 exit() 而是直接 await 长操作再返回,一方面会长时间持有数据库事务造成锁竞争,另一方面操作完成前事务始终未提交,任务记录不会入库。
为什么要重新查询任务,而不是直接使用 saveJob 返回的对象?
saveJob 返回的是绑定在原事务上的内存模型实例,processor.exit() 调用后该事务已提交关闭。直接修改此实例并调用 resume 会导致 ORM 状态异常(事务引用失效、状态不一致等)。通过 id 重新从数据库查询可确保获得干净的、与任何事务无关的新实例。
为什么 run 函数不返回任何值(void)?
processor.exit() 已被手动调用,执行器收到 void 后调用 exit(true) 立即退出,不做任何重复处理。若此时返回 IJob,执行器会再次尝试保存并提交,导致错误。详见 run/resume 返回值章节。
对于需要外部回调的场景(如 webhook 通知的支付结果),同样应先调用 processor.exit() 再注册回调,确保任务记录在外部系统回调前已入库,在回调中再按 id 重新查询任务后调用 this.workflow.resume(job)。
实际项目中的完整示例可参考:RequestInstruction.ts(HTTP 请求节点,在非同步工作流中使用了此模式)
节点的结果状态
节点的执行状态会影响整个流程的成功或失败,通常在没有分支的情况下,某个节点的失败会直接导致整个流程失败。其��中最常规的情况是,节点执行成功则继续节点表中的下一个节点,直到没有后续节点,则整个工作流执行以成功的状态完成。
如果执行中某个节点返回了执行失败的状态,则视以下两种情况引擎会有不同的处理:
-
返回失败状态的节点处于主流程,即均未处于上游的节点开启的任意分支流程之内,则整个主流程会判定为失败,并退出流程。
-
返回失败状态的节点处于某个分支流程之内,此时将判定流程下一步状态的职责交由开启分支的节点,由该节点的内部逻辑决定后续流程的状态,并且递归上溯到主流程。
最终都在主流程的节点上得出整个流程的下一步状态,如果主流程的节点中返回的是失败,则整个流程以失败的状态结束。
如果任意节点执行后返回了"停等"状态,则整个执行流程会被暂时中断挂起,等待一个由对应节点定义的事件触发以恢复流程的执行。例如人工节点,执行到该节点后会以"停等"状态从该节点暂停,等待人工介入该流程,决策是否通过。如果人工输入的状态是通过,则继续后续的流程节点,反之则按前面的失败逻辑处理。
更多的的指令返回状态可以参考工作流 API 参考部分。
run/resume 返回值类型与执行器行为
run 和 resume 方法的完整返回类型定义为:
执行器(Processor)在调用指令后,根据返回值的类型执行不同的处理逻辑,共有三种情况。
1. 返回任务对象 IJob
这是最常见的情况,返回一个包含 status(必须)和可选 result 字段的对象。执行器将其保存为节点的任务记录,并根据 status 值决定后续流向:
JOB_STATUS.RESOLVED:节点成功执行,若有下游节点则继续运行,否则流程结束JOB_STATUS.PENDING:节点进入挂起状态,当前执行上下文中止,等待外部事件触发resume- 其他失败状态(
FAILED、ERROR等):向上传递给分支父节点或直接结束整个流程
此路径是完整的事务提交路径——执行器会保存任务记录、写库并提交事务。
示例参考:ConditionInstruction.ts(无分支时直接返回 job 对象,有分支时见下文 void 情况)
2. 返回 null
返回 null 时,执行器调用 processor.exit()(不传参数),其效果是:将当前待写入的任务刷入数据库并提交事务,但不更新整体执行的状态。
这种用法常见于分支控制节点的 resume 方法:某个分支已完成,需要更新并保存父节点的任务状态(例如记录"第 N 个分支已完成"),但其他分支仍在运行,整体执行应继续保持 STARTED 状态等待剩余分支——此时返回 null 退出当前 resume 上下文而不影响整体执行状态。
- 第 117 行:并行节点已提前完成(resolved/rejected),忽略后续分支的 resume,直接返回
null - 第 135 行:仍有分支未完成(
PENDING),保存当前进度后返回null,继续等待其��他分支
3. 返回 void(不返回,即隐式 undefined)
返回 void(函数没有显式返回语句,或执行路径结束时无返回值)时,执行器调用 processor.exit(true),效果是立即返回,不执行任何数据库操作。
这种模式专用于指令已自行接管执行调度的场景:指令内部通过 processor.run() 手动启动了子流程,子流程的执行链自身会在完成时负责数据库写入和事务提交,执行器不应再重复处理。
典型例子:
- ConditionInstruction.ts#L67:有分支时手动调用
processor.run(branchNode, savedJob)后函数结束,隐式返回void - ParallelInstruction.ts#L108:遍历所有分支并依次调用
processor.run(branch, job)后函数结束,隐式返回void
:::warn{title=提示}
返回 void 之前如果调用了 processor.saveJob(),这些任务记录不会由当前执行器写库。它们被暂存在执行器任务列表(内存)中,将由后续手动调用的 processor.run() 完成执行时触发的 exit() 统一刷入数据库。因此使用此模式时,必须确保存在会正常结束的子执行路径来完成这些记录的持久化。分支流程的调度有一定复杂性,需要谨慎设计并进行充分的测试。
:::
三种返回值的对比汇总:
了解更多
定义节点类型的各个参数定义见工作流 API 参考部分。
客户端
与触发器类似,指令(节点类型)的配置表单需要在前端实现。
最简单的节点指令
所有的指令都需要派生自 Instruction 基类,相关属性和方法用于对节点的配置和使用。
例如我们需要为上面在服务端定义的随机数字符串类型(randomString)的节点提供配置界面,其中有一个配置项是 digit 代表随机数的位数。
其中 FieldsetLoader 是一个返回 Promise<{ default: ComponentType }> 的函数,通过动态 import() 实现懒加载。它指向的组件是一个标准的 React 函数组件,使用 antd 的 Form.Item 构建表单:
注意表单字段的 name 使用嵌套数组格式 ['config', '字段名'],这是 antd Form 的标准写法。
多个配置界面
节点可以提供多个配置界面,分别用于不同的场景:
-
FieldsetLoader— 节点配置抽屉表单(最常用)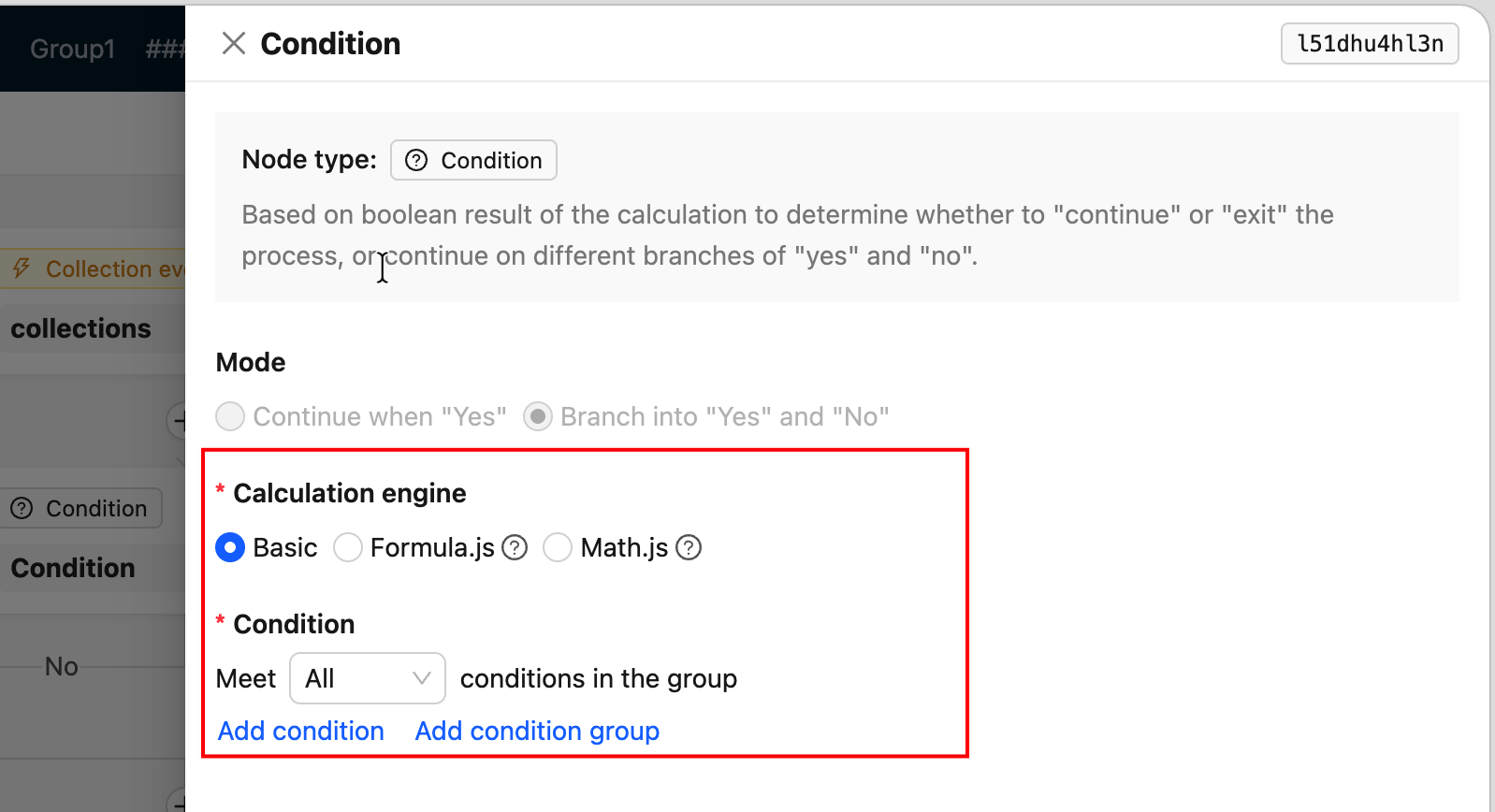
-
PresetFieldsetLoader— 创建节点时的预设表单(通常只包含必填项)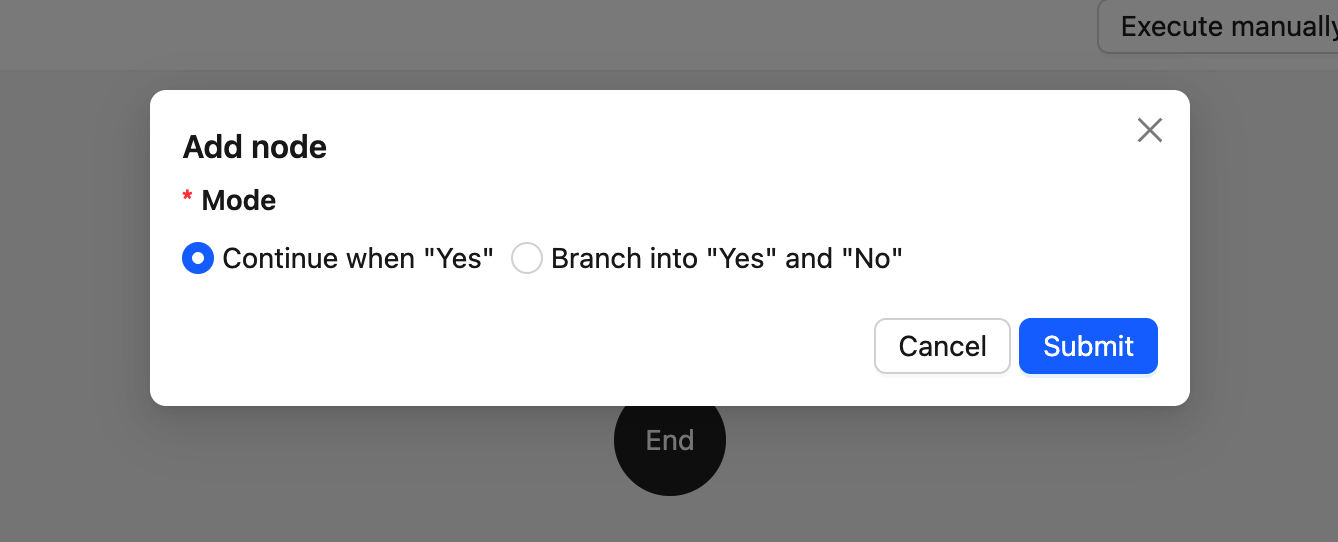
-
ComponentLoader— 画布上自定义节点渲染(用于分支节点等需要特殊渲染的情况)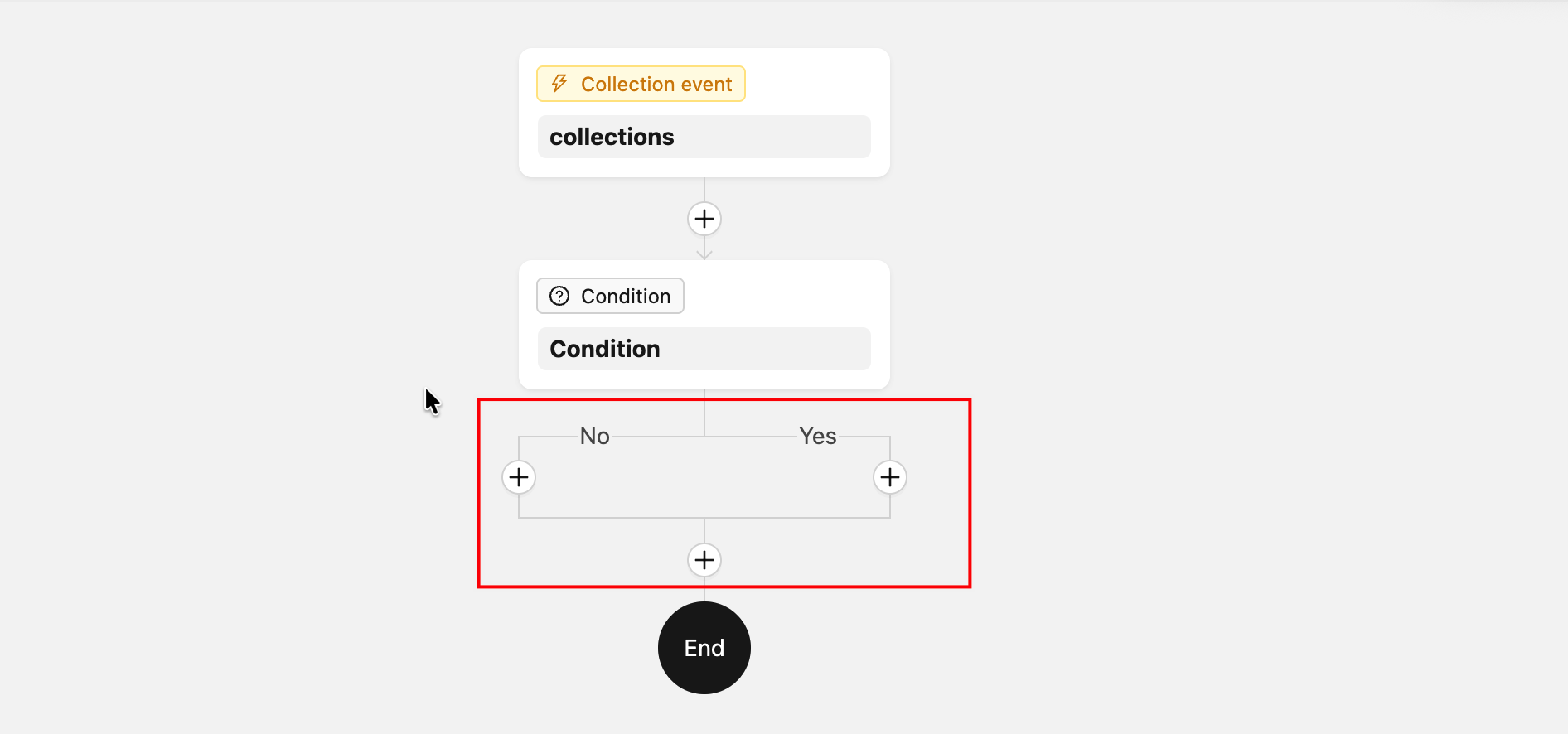
当 Loader 需要指向文件中的命名导出(而非默认导出)时,使用 .then() 重映射:
注册节点
在扩展的插件内向工作流插件实例注册节点类型:
客户端注册的节点类型标识必须与服务端的保持一致,否则会导致错误。
提供节点的结果作为变量
可以注意到上面例子中的 useVariables 方法,如果需要将节点的结果(result 部分)作为变量供后续节点使用,需要在继承的指令类中实现该方法,并返回一个符合 VariableOption 类型的对象,该对象作为对节点运行结果的结构描述,提供变量名映射,以供后续节点中进行选择使用。
其中 VariableOption 类型定义如下:
核心是 value 属性,代表变量名的分段路径值,label 用于显示在界面上,children 用于表示多层级的变量结构,当节点的结果是一个深层对象时会使用。
一个可使用的变量在系统内部的表达是一个通过 . 分隔的路径模板字符串,例如 {{$jobsMapByNodeKey.2dw92cdf.abc}}。其中 $jobsMapByNodeKey 表示的是所有节点的结果集(已内部定义,无需处理),2dw92cdf 是节点的 key,abc 是节点的结果对象中的某个自定义属性。
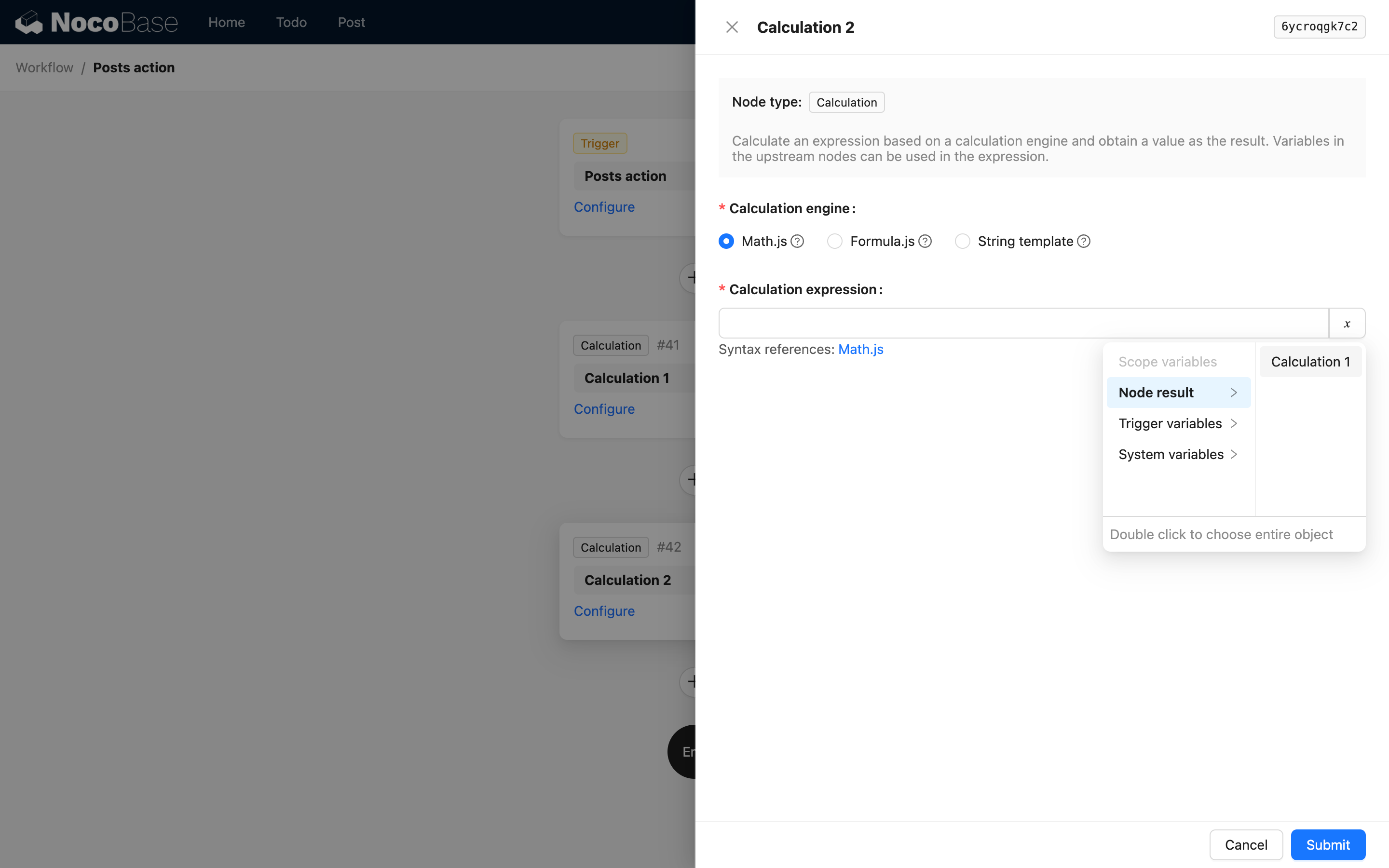
另外,由于节点的结果也可能是一个简单值,所以要求提供节点变量时,第一层必须是节点本身的描述:
即第一层是节点的 key 和标题。例如运算节点的代码参考,则在使用运算节点的结果时,界面的选项如下:
当节点的结果是一个复杂对象时,可以通过 children 继续描述深层属性,例如一个自定义指令会返回如下的 JSON 数据:
则可以通过如下的 useVariables 方法返回:
这样在后续节点中就可以用以下的界面来选择其中的变量:
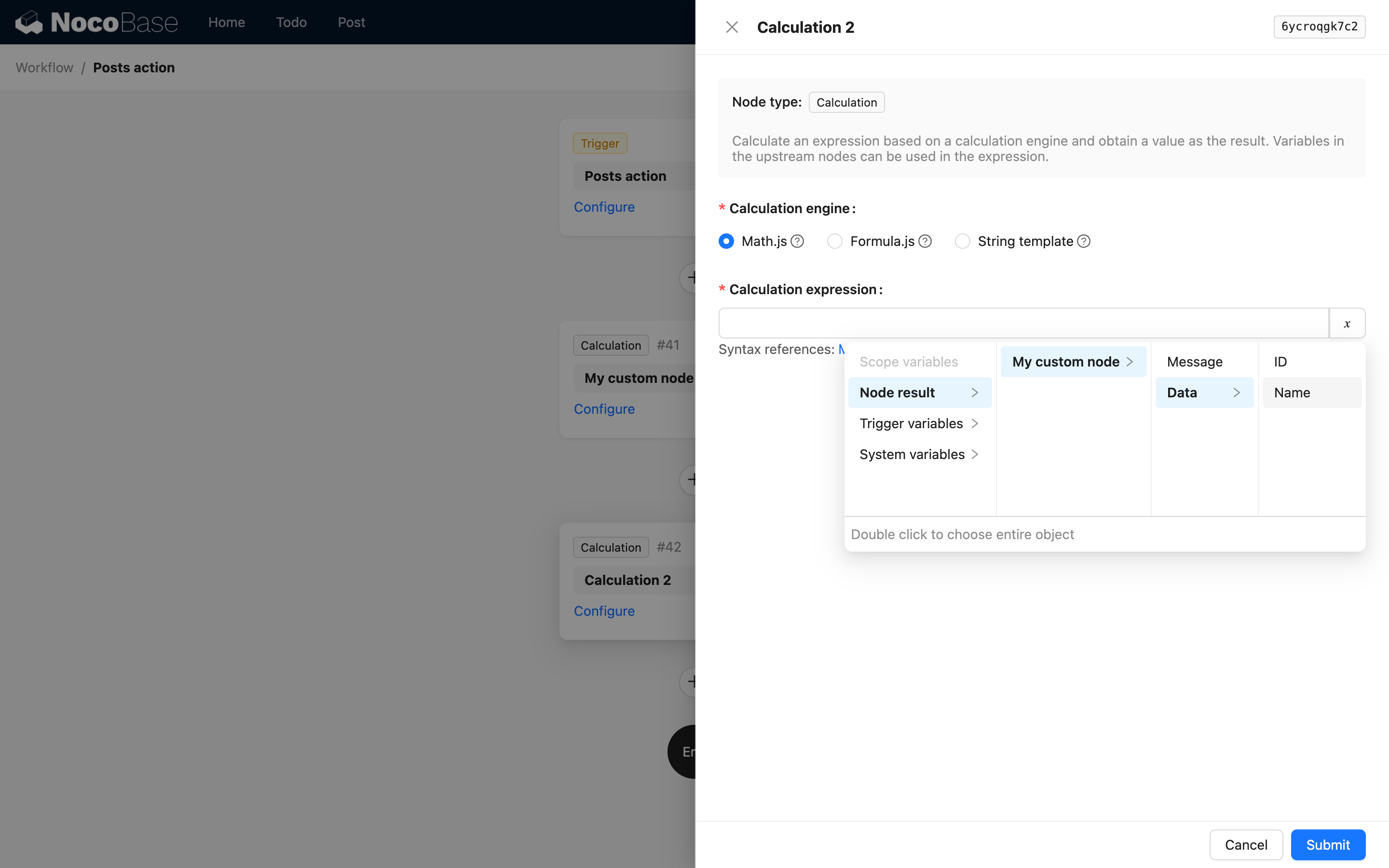
当结果中某个结构是深层对象数组时,同样可以使用 children 来描述路径,但不能包含数组索引,因为在 NocoBase 工作流的变量处理中,针对对象数组的变量路径描述,在使用时会自动扁平化为深层值的数组,而不能通过索引来访问第几个值。
节点是否可用
默认情况下,工作流中可以任意添加节点。但在某些情况下,节点在一些特定类型的工作流或者分支内是不适用的,这时可以通过 isAvailable 来配置节点的可用性:
isAvailable 方法返回 true 时表示节点可用,false 表示不可用。ctx 参数中包含了当前节点的上下文信息,可以根据这些信息来判断节点是否可用。
在没有特殊需求的情况下,不需要实现 isAvailable 方法,节点默认是可用的。最常见需要配置的情况,是节点可能是一个高耗时的操作,不适合在同步流程中执行,可以通过 isAvailable 方法来限制节点的使用。例如:
了解更多
实际项目中的完整示例可参考:CalculationInstruction 源码
定义节点类型的各个参数定义见 工作流 API 参考 部分。
如果你之前使用的是旧版(v1)的客户端代码,想迁移到 v2 新版的话,可以参考 v1 到 v2 迁移指南。