

Import Pro
Action: Import records ProStandard Edition+Introduction
Le plugin Import Pro fournit des fonctionnalités étendues sur la base de la fonctionnalité d'importation classique.
Installation
Ce plugin dépend du plugin de gestion des tâches asynchrones ; vous devez activer le plugin de gestion des tâches asynchrones avant de l'utiliser.
Améliorations fonctionnelles
- Prend en charge les opérations d'importation asynchrones, exécutées dans un thread indépendant, et permet d'importer de gros volumes de données.
- Prend en charge les options d'importation avancées.
Manuel d'utilisation
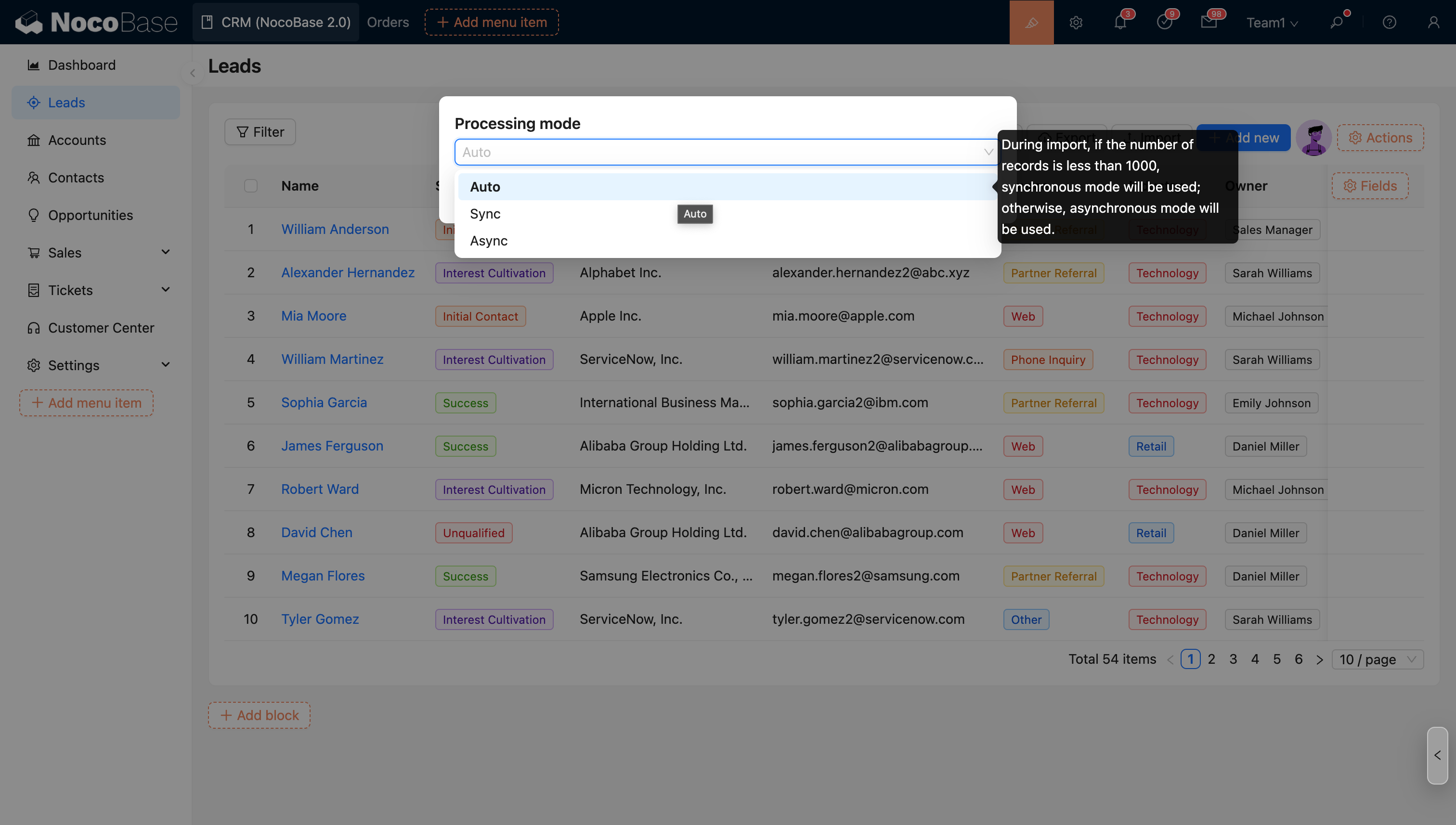
Importation asynchrone
Après le déclenchement de l'importation, le processus d'importation s'exécute dans un thread d'arrière-plan indépendant, sans configuration manuelle de votre part. Dans l'interface utilisateur, après l'exécution de l'importation, la tâche d'importation en cours d'exécution s'affiche en haut à droite, avec sa progression mise à jour en temps réel.
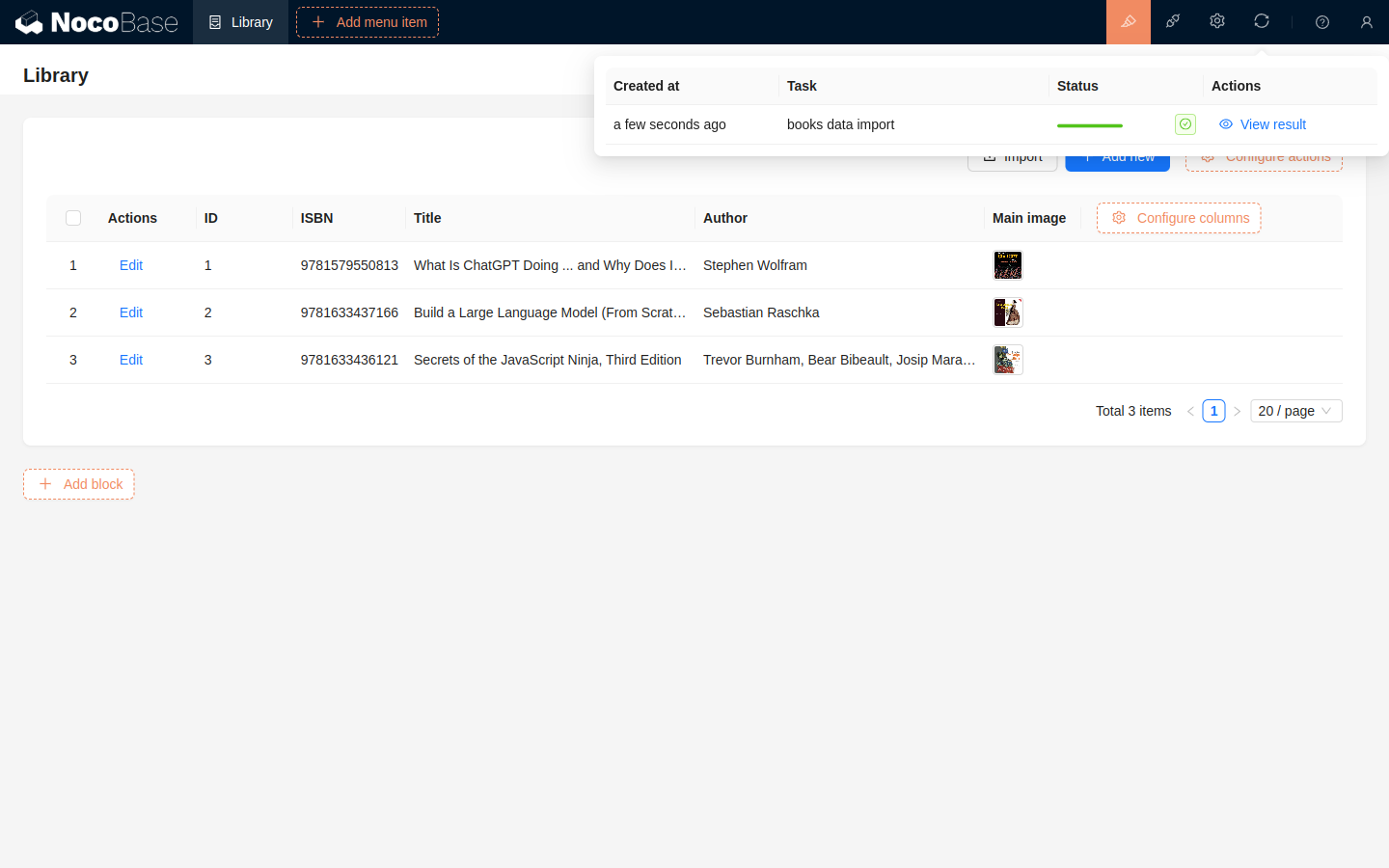
Une fois l'importation terminée, vous pouvez consulter le résultat dans la liste des tâches d'importation.
À propos de la concurrence
Si vous souhaitez limiter la consommation de ressources système liée à l'exécution simultanée de tâches asynchrones, vous pouvez utiliser les variables d'environnement suivantes :
ASYNC_TASK_MAX_CONCURRENCY
Limite le nombre de tâches asynchrones exécutées simultanément, valeur par défaut : 3
ASYNC_TASK_CONCURRENCY_MODE
Spécifie le mode de limitation d'exécution simultanée, valeurs possibles : app et process, valeur par défaut : app.
Lorsque cette variable d'environnement est définie sur app, le nombre maximal de tâches asynchrones pouvant être exécutées simultanément par chaque sous-application est limité à la valeur spécifiée par ASYNC_TASK_MAX_CONCURRENCY.
Lorsque cette variable d'environnement est définie sur process, la somme des tâches exécutées simultanément par toutes les sous-applications du processus ne peut pas dépasser la valeur spécifiée par ASYNC_TASK_MAX_CONCURRENCY.
ASYNC_TASK_WORKER_MAX_OLDetASYNC_TASK_WORKER_MAX_YOUNG
Limitent la mémoire heap maximale (en Mo) allouable à la génération ancienne et à la nouvelle génération du thread worker exécutant les tâches asynchrones.
À propos des performances
Pour évaluer les performances de l'importation de données à grande échelle, nous avons effectué des tests comparatifs dans différents scénarios, types de champs et configurations de déclenchement (les résultats peuvent varier selon les configurations de serveur et de base de données, ces données sont fournies à titre indicatif) :
Sur la base de ces résultats de test de performance et de certaines conceptions actuelles, voici quelques explications et recommandations sur les facteurs d'influence :
-
Mécanisme de traitement des enregistrements en doublon : lorsque vous sélectionnez l'option Mettre à jour les enregistrements en doublon ou Mettre à jour uniquement les enregistrements en doublon, le système exécute des opérations de requête et de mise à jour ligne par ligne, ce qui réduit considérablement l'efficacité de l'importation. Si votre fichier Excel contient des données en doublon inutiles, cela aggrave encore l'impact sur la vitesse d'importation. Il est recommandé de nettoyer les données en doublon inutiles dans Excel avant l'importation (par exemple à l'aide d'un outil professionnel de déduplication), puis d'importer dans le système ; cela évite de gaspiller du temps inutilement.
-
Efficacité du traitement des champs de relation : le système traite les champs de relation en exécutant des requêtes d'association ligne par ligne, ce qui devient un goulot d'étranglement pour les performances dans des scénarios de gros volumes de données. Pour les structures de relation simples (par exemple une relation un-à-plusieurs entre deux collections), il est recommandé d'adopter une stratégie d'importation en plusieurs étapes : importez d'abord les données de base de la collection principale, puis établissez les relations entre collections une fois cette étape terminée. Si les exigences métier imposent d'importer simultanément les données de relation, planifiez raisonnablement le temps d'importation en vous référant aux résultats des tests de performance ci-dessus.
-
Mécanisme de traitement des workflows : il n'est pas recommandé d'activer le déclenchement de workflows lors de l'importation de gros volumes de données, principalement pour les deux raisons suivantes :
- Le statut de la tâche d'importation affichant 100 % ne signifie pas que la tâche se termine immédiatement ; le système a encore besoin de temps supplémentaire pour créer les plans d'exécution des workflows. À ce stade, le système génère un plan d'exécution de workflow pour chaque enregistrement importé, ce qui occupe le thread d'importation, mais n'affecte pas l'utilisation des données déjà importées.
- Une fois la tâche d'importation complètement terminée, l'exécution simultanée d'un grand nombre de workflows peut entraîner une saturation des ressources système, affectant la vitesse de réponse globale et l'expérience utilisateur.
Ces 3 facteurs feront l'objet d'optimisations supplémentaires ultérieurement.
Configuration d'importation
Option d'importation - Déclencher ou non le workflow
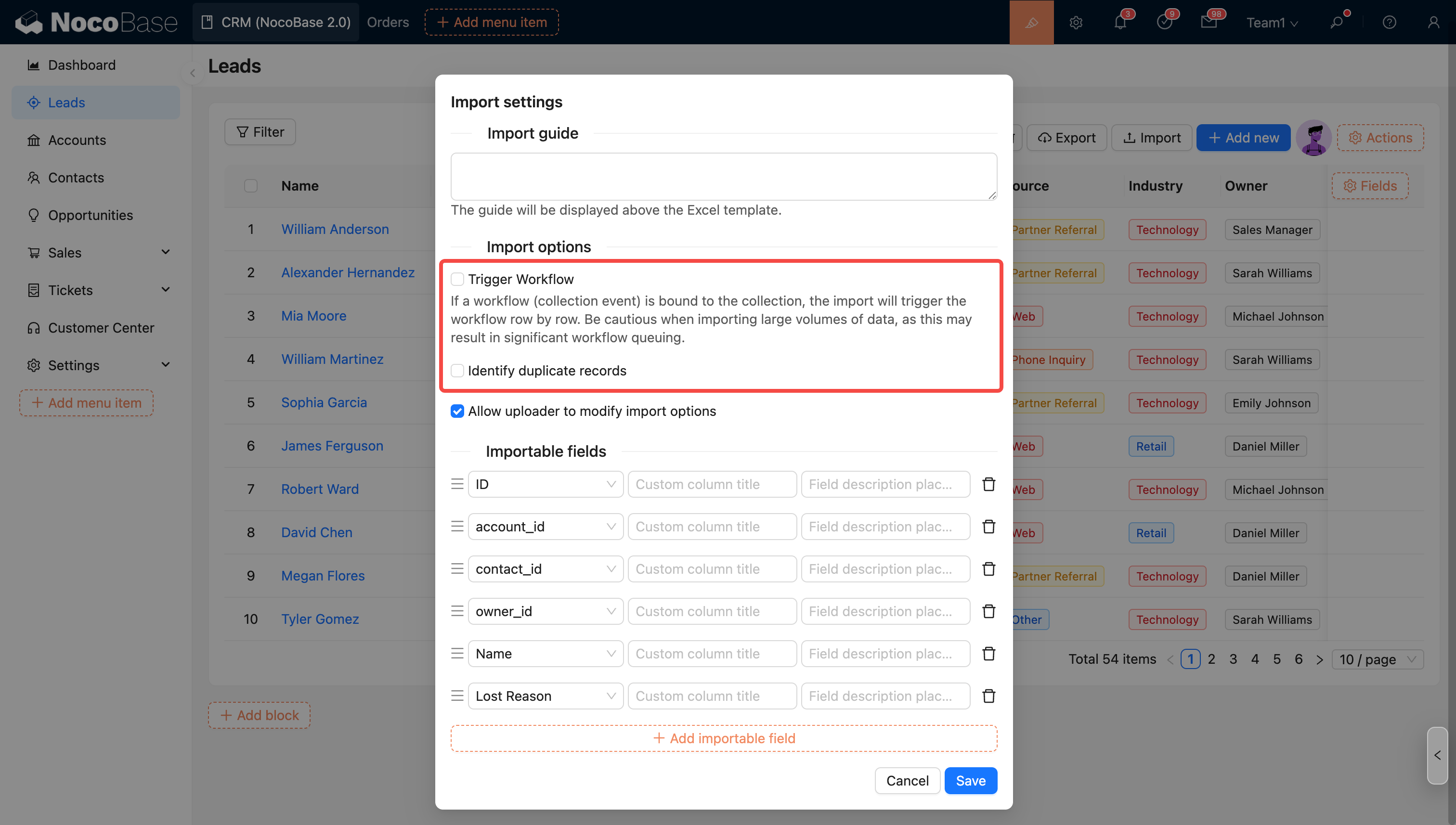
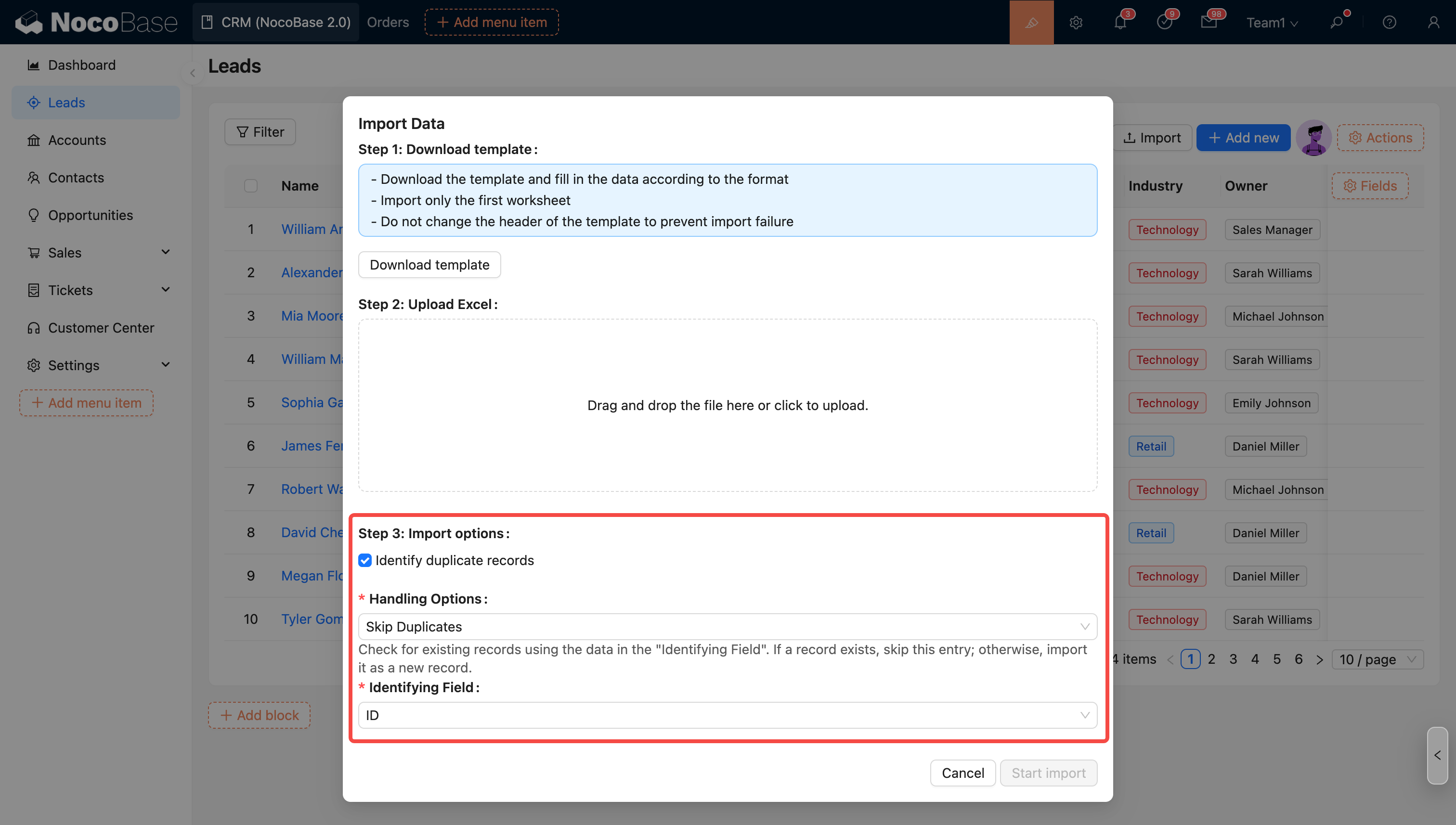
Lors de l'importation, vous pouvez choisir de déclencher ou non un workflow. Si cette option est cochée et que la collection est liée à un workflow (événement de collection), l'importation déclenchera l'exécution du workflow ligne par ligne.
Option d'importation - Identifier les enregistrements en doublon
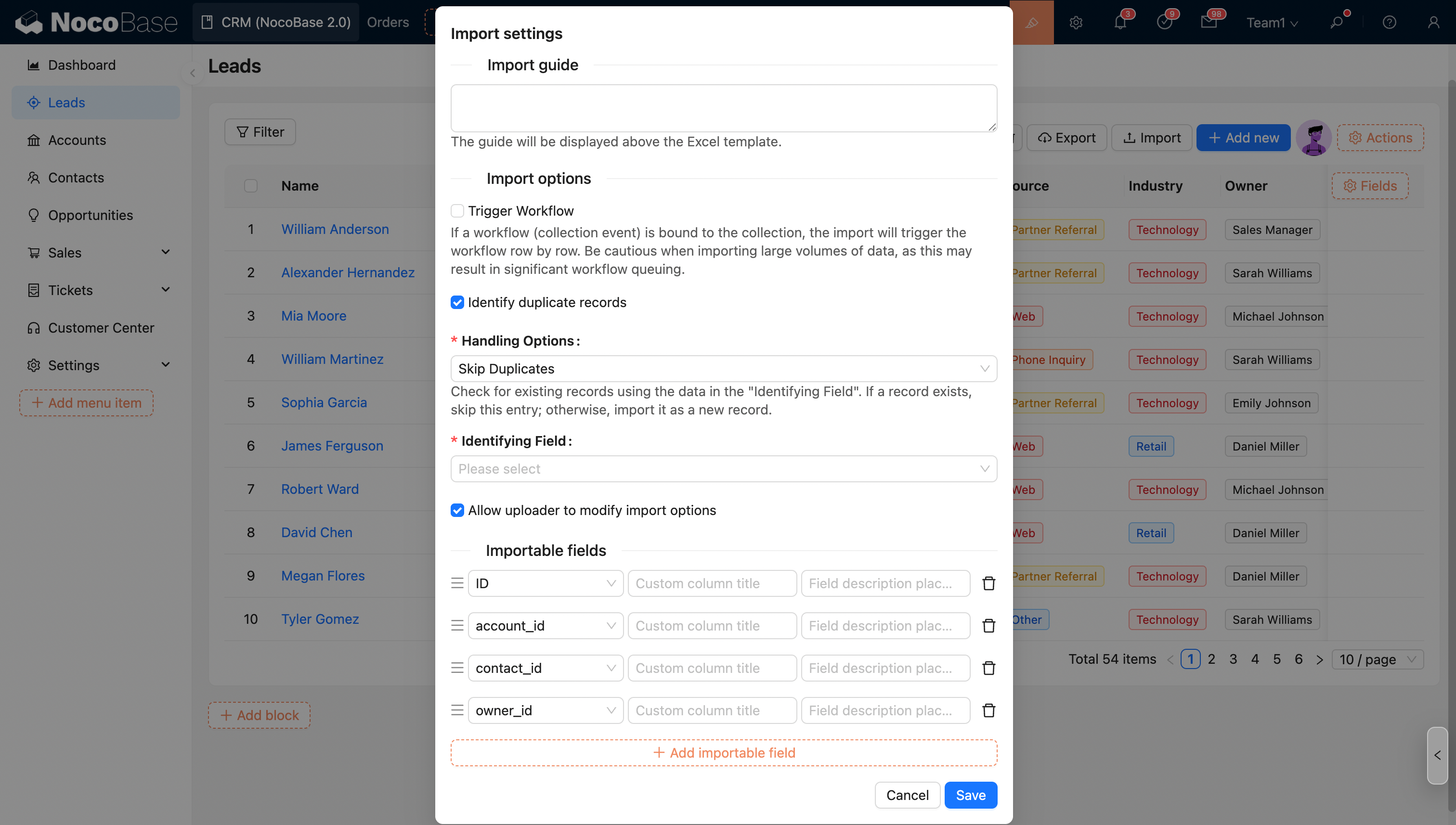
Si cette option est cochée, en sélectionnant le mode correspondant, l'importation identifiera les enregistrements en doublon et les traitera.
Les options de la configuration d'importation seront appliquées comme valeurs par défaut, et l'administrateur peut contrôler si l'utilisateur effectuant l'importation est autorisé à modifier ces options (à l'exception de l'option de déclenchement du workflow).
Paramètres d'autorisation pour l'utilisateur effectuant l'importation
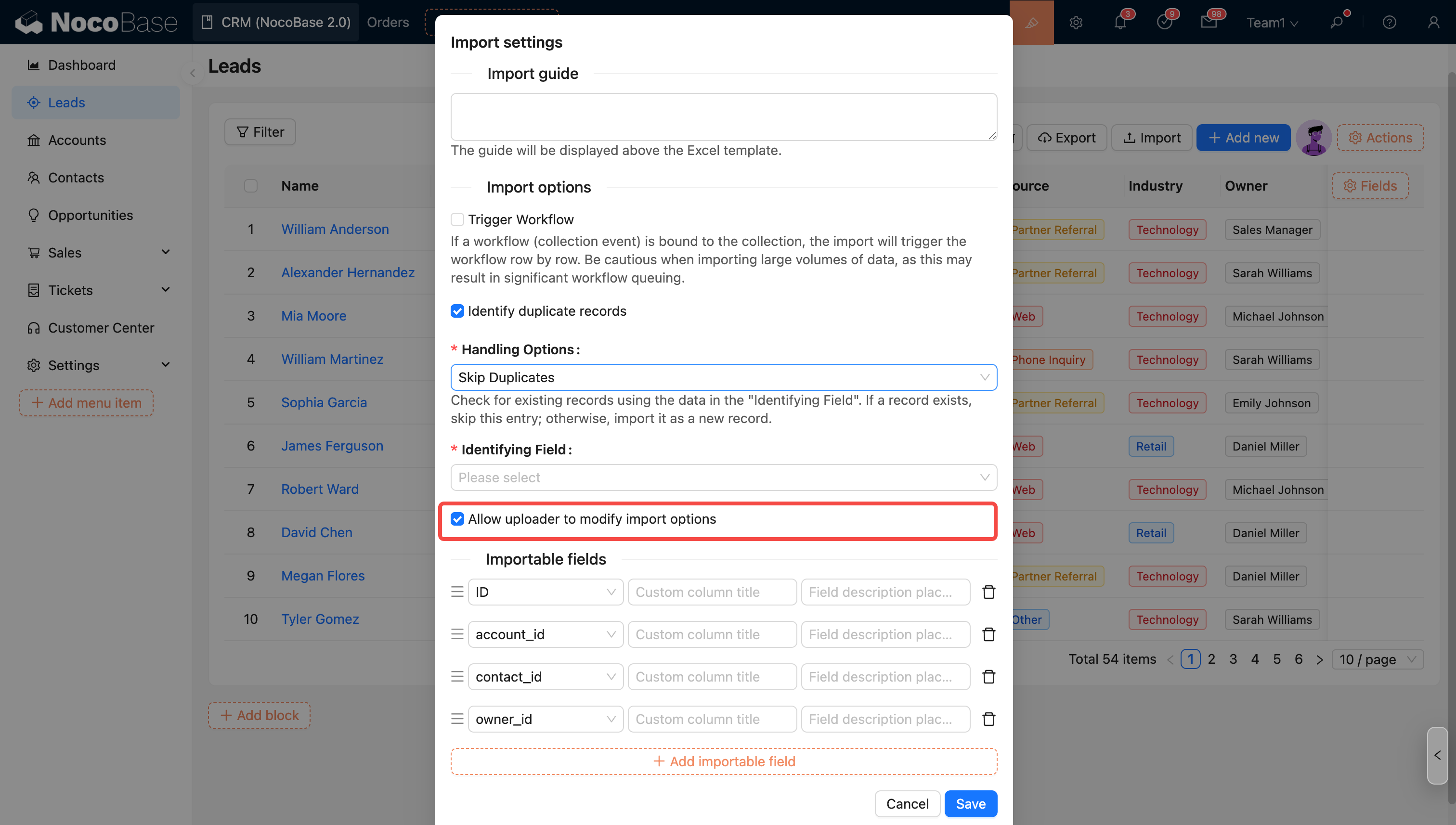
- Autoriser l'utilisateur à modifier les options d'importation
- Empêcher l'utilisateur de modifier les options d'importation
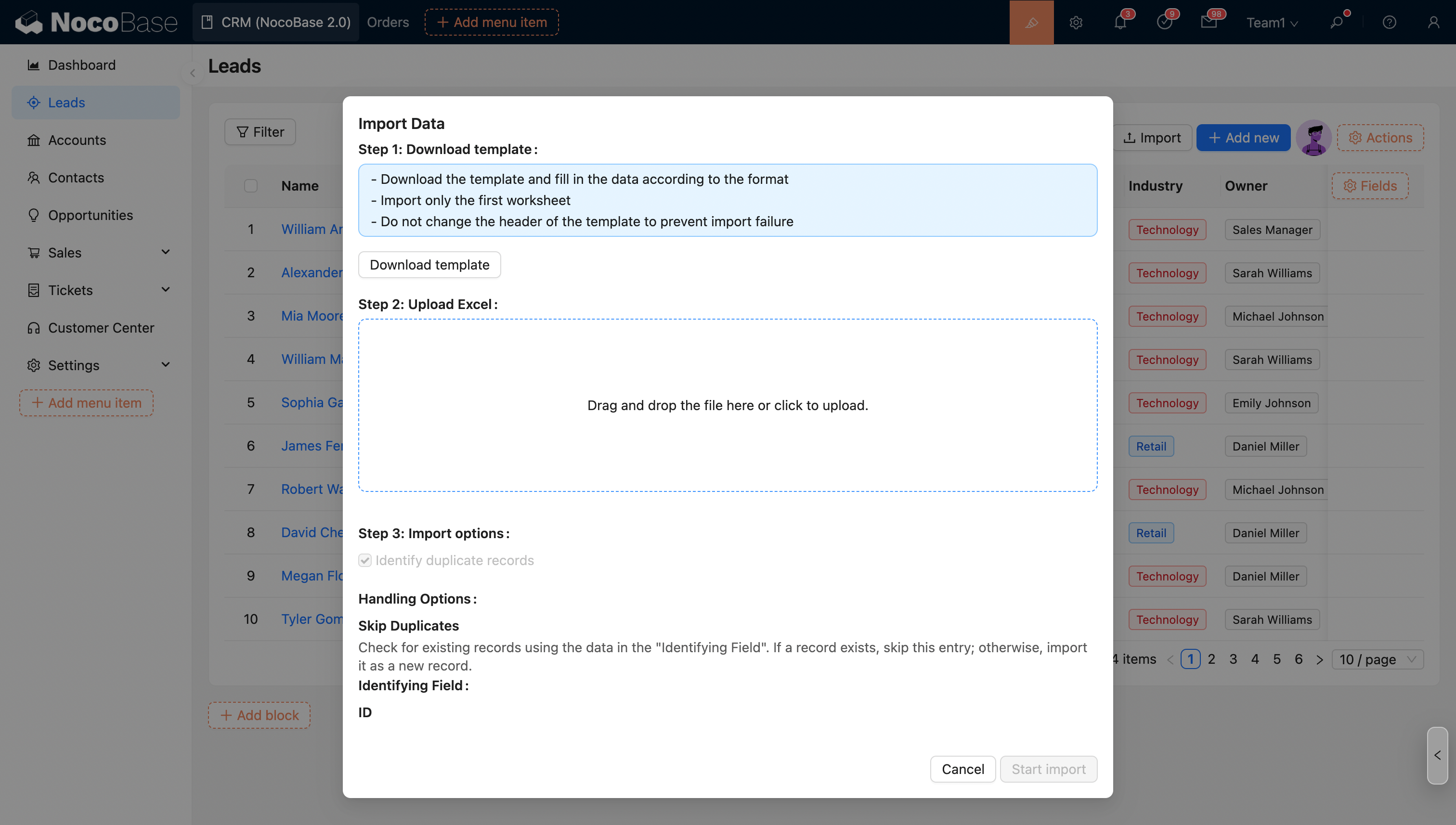
Description des modes
- Ignorer les enregistrements en doublon : recherche les enregistrements existants en fonction du contenu du «champ de référence» ; si l'enregistrement existe, ignore directement cette ligne ; sinon, l'importe comme un nouvel enregistrement.
- Mettre à jour les enregistrements en doublon : recherche les enregistrements existants en fonction du contenu du «champ de référence» ; si l'enregistrement existe, met à jour cette ligne ; sinon, l'importe comme un nouvel enregistrement.
- Mettre à jour uniquement les enregistrements en doublon : recherche les enregistrements existants en fonction du contenu du «champ de référence» ; si l'enregistrement existe, le met à jour ; sinon, l'ignore.
Champ de référence
Le système identifie si une ligne est un enregistrement en doublon en fonction de la valeur de ce champ.
- Règle de liaison : afficher / masquer le bouton dynamiquement ;
- Modifier le bouton : modifier le titre, le type et l'icône du bouton.