

Импорт Про
Действие: импорт записей ProStandard Edition+Введение
Плагин «Импорт Про» предоставляет расширенные возможности поверх стандартной функции импорта.
Установка
Этот плагин зависит от плагина «Менеджер асинхронных задач». Перед использованием нужно включить плагин «Менеджер асинхронных задач».
Расширения функций
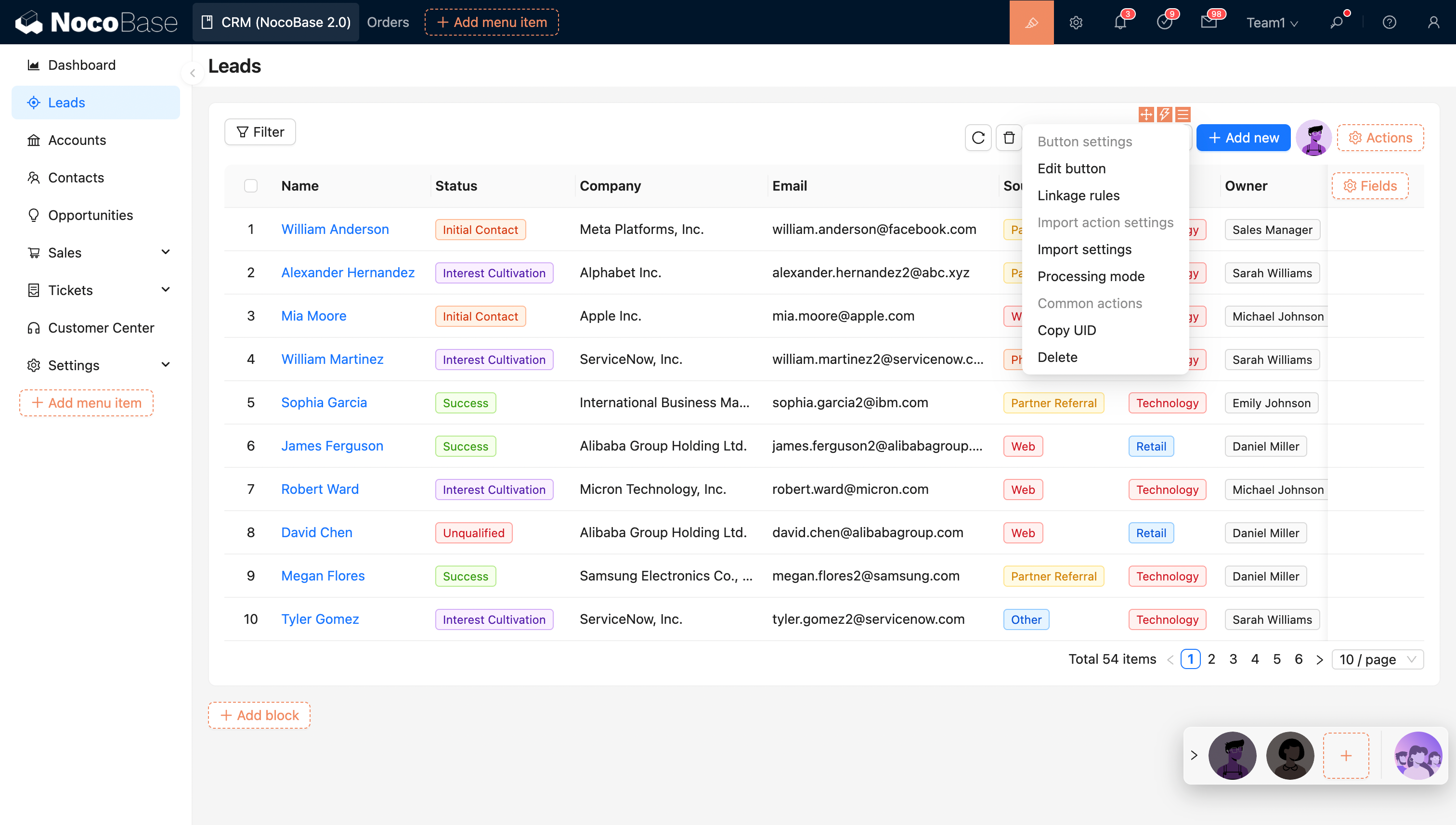
- Поддерживает асинхронные операции импорта, выполняемые в отдельном потоке, а также импорт больших объёмов данных.
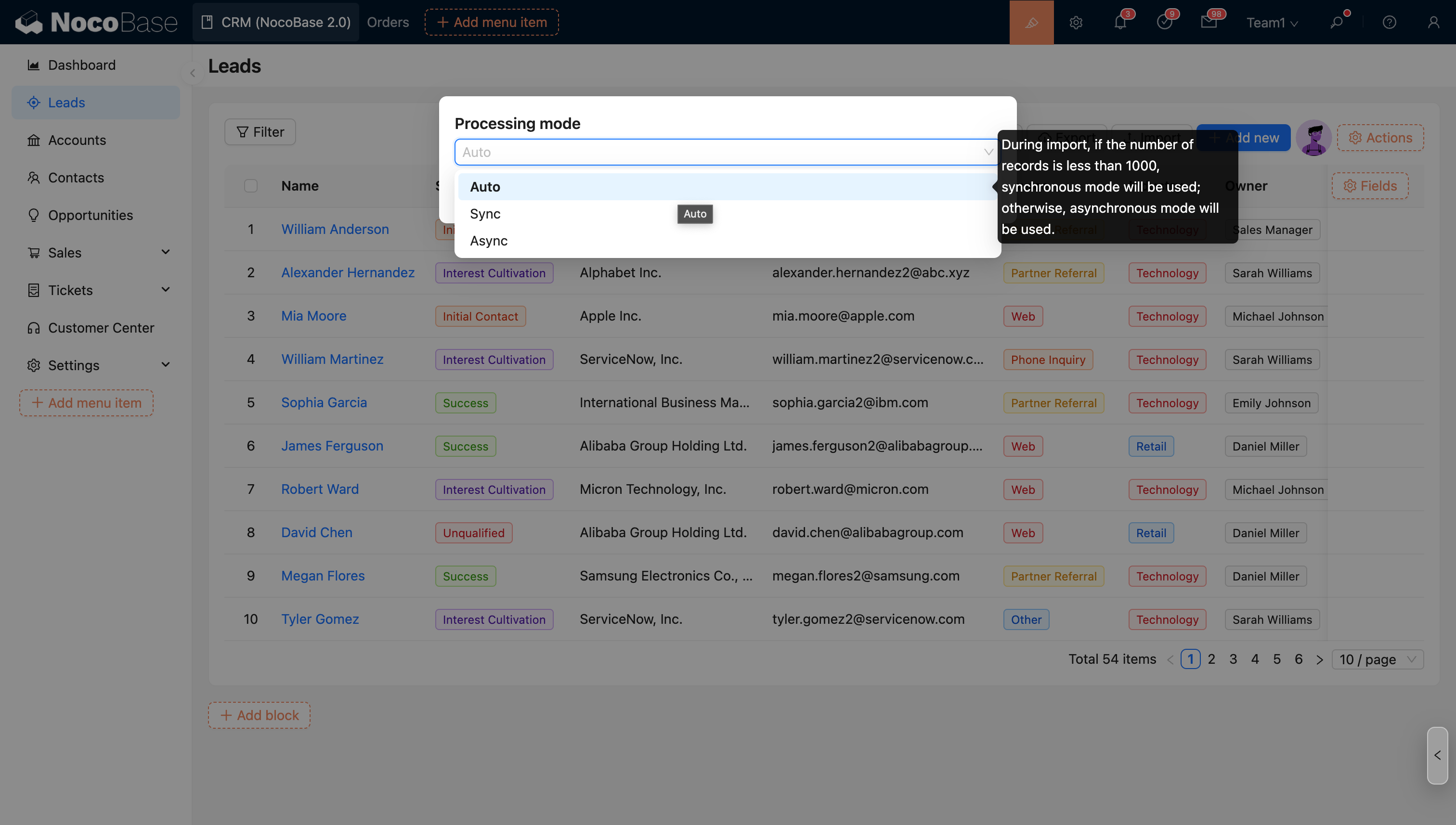
- Поддерживает расширенные параметры импорта.
Руководство пользователя
Асинхронный импорт
После выполнения импорта процесс будет выполняться в отдельном фоновом потоке без необходимости ручной настройки пользователя. В интерфейсе после старта импорта текущая выполняемая задача импорта будет отображаться в правом верхнем углу, показывая прогресс в реальном времени.
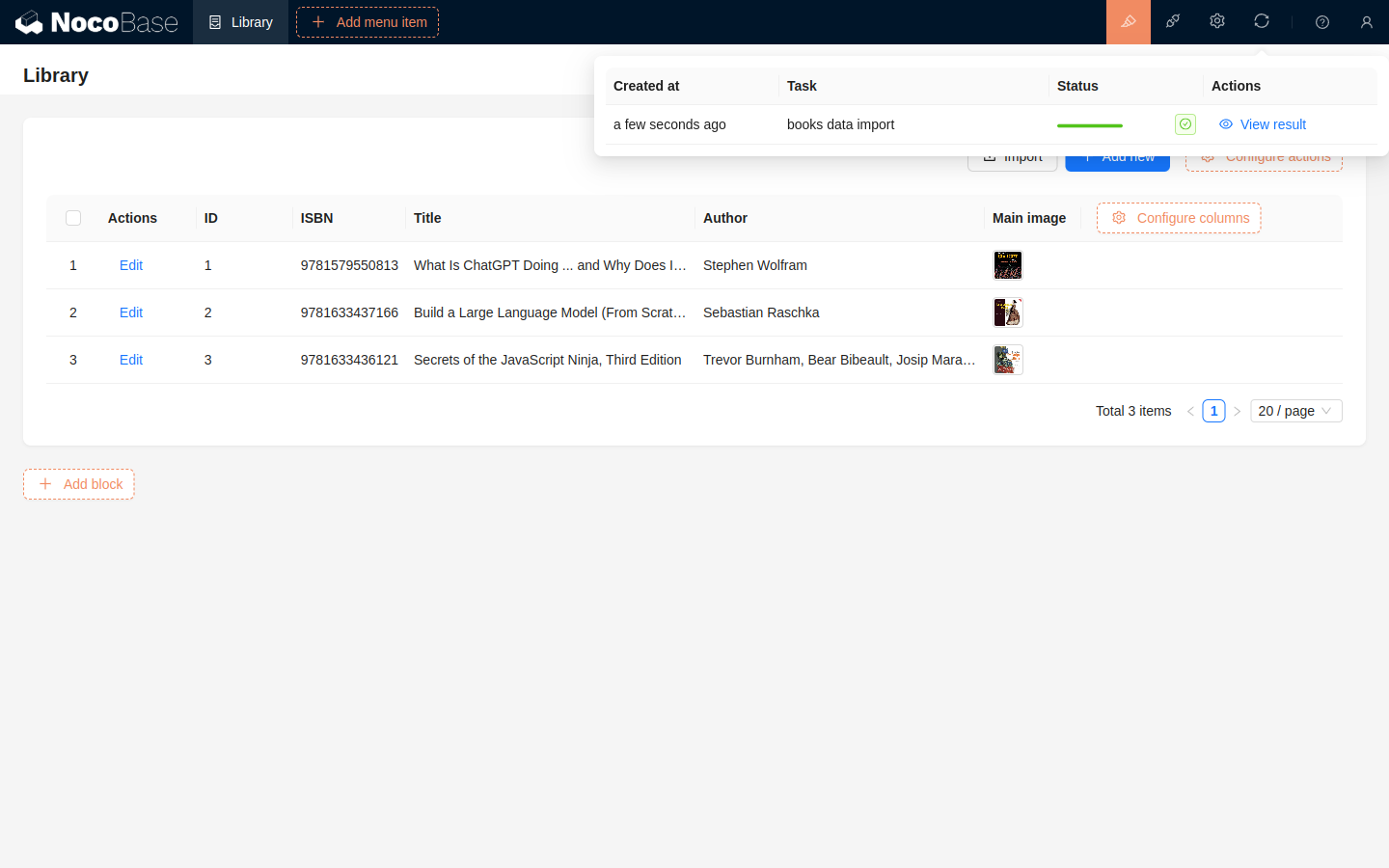
После завершения импорта вы можете просмотреть результаты в задачах импорта.
О производительности
Чтобы оценить производительность импортирования больших объёмов данных, мы провели сравнительные тесты в разных сценариях, типах полей и конфигурациях триггеров (результаты могут отличаться в зависимости от конфигурации сервера и базы данных; это справочные данные):
По результатам тестов выше и с учётом некоторых существующих решений, ниже приведены объяснения и рекомендации по факторам, влияющим на производительность:
-
Механизм обработки дубликатов записей: при выборе опций Обновлять дубликаты записей или Обновлять только дубликаты система выполняет операции запроса и обновления построчно, что существенно снижает эффективность импорта. Если ваш файл электронных таблиц содержит ненужные данные-дубликаты, это дополнительно влияет на скорость. Рекомендуется очистить файл электронных таблиц от ненужных данных-дубликатов (например, используя профессиональные �инструменты дедупликации) перед импортом в систему, чтобы не тратить время.
-
Эффективность обработки полей связей: система обрабатывает поля связей, запрашивая ассоциации построчно, что в сценариях с большим объёмом данных может стать узким местом. Для простых структур связей (например, связь «один-ко-многим» между двумя коллекциями) рекомендуется использовать многоэтапную стратегию импорта: сначала импортировать базовые данные основной коллекции, а затем установить связь между коллекциями после завершения этого шага. Если по бизнес-требованиям нужно импортировать данные связей одновременно, используйте результаты тестов производительности из таблицы выше, чтобы разумно спланировать время импорта.
-
Механизм запуска рабочего процесса: не рекомендуется включать триггеры рабочего процесса при импорте больших объёмов данных, в первую очередь по следующим причинам:
- Даже когда статус задачи импорта показывает 100 %, она не завершится сразу. Системе всё ещё нужно дополнительное время, чтобы создать планы выполнения рабочего процесса. На этом этапе система �генерирует соответствующий план выполнения рабочего процесса для каждой импортируемой записи, что занимает поток импорта, но не влияет на использование уже импортированных данных.
- После полного завершения задачи импорта одновременное выполнение большого числа рабочих процессов может нагрузить системные ресурсы, ухудшая общую отзывчивость системы и пользовательский опыт.
Эти три фактора будут учитываться для дальнейшей оптимизации.
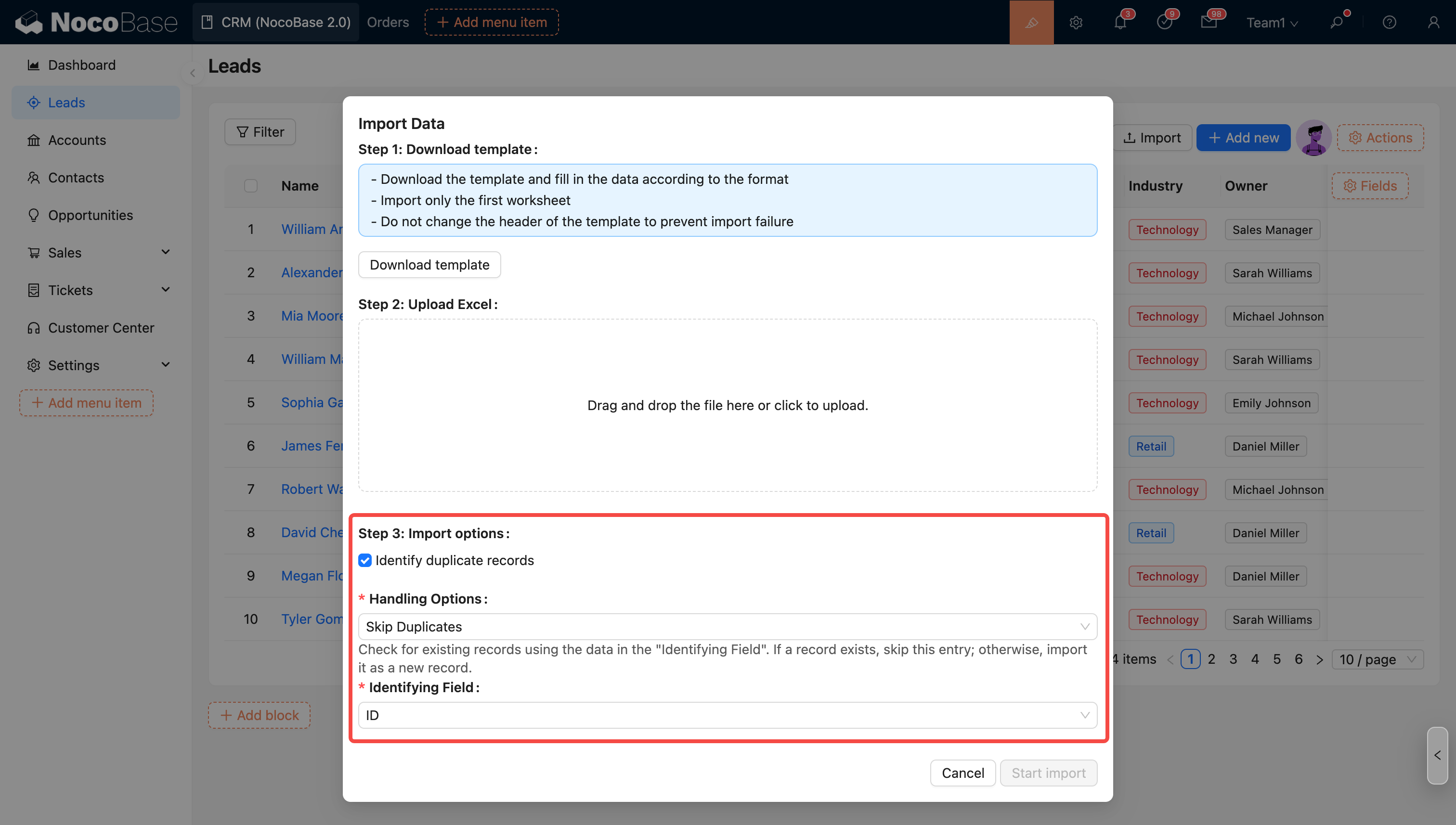
Конфигурация импорта
Параметры импорта — запуск рабочего процесса
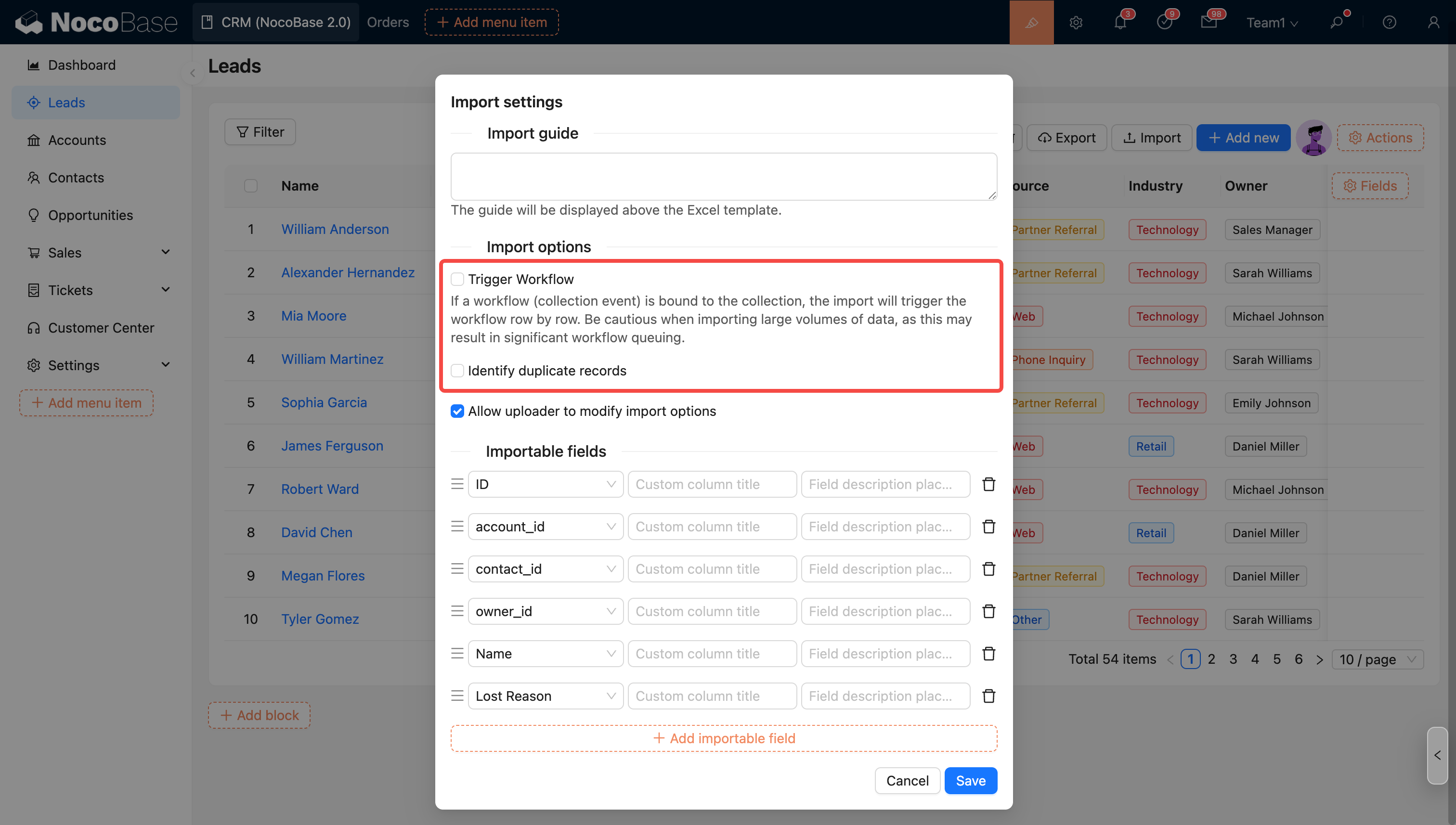
Вы можете выбрать, запускать ли рабочий процесс во время импорта. Если этот параметр включён и коллекция привязана к рабочему процессу (событие коллекции), импорт будет запускать выполнение рабочего процесса для каждой строки.
Параметры импорта — идентификация дубликатов записей
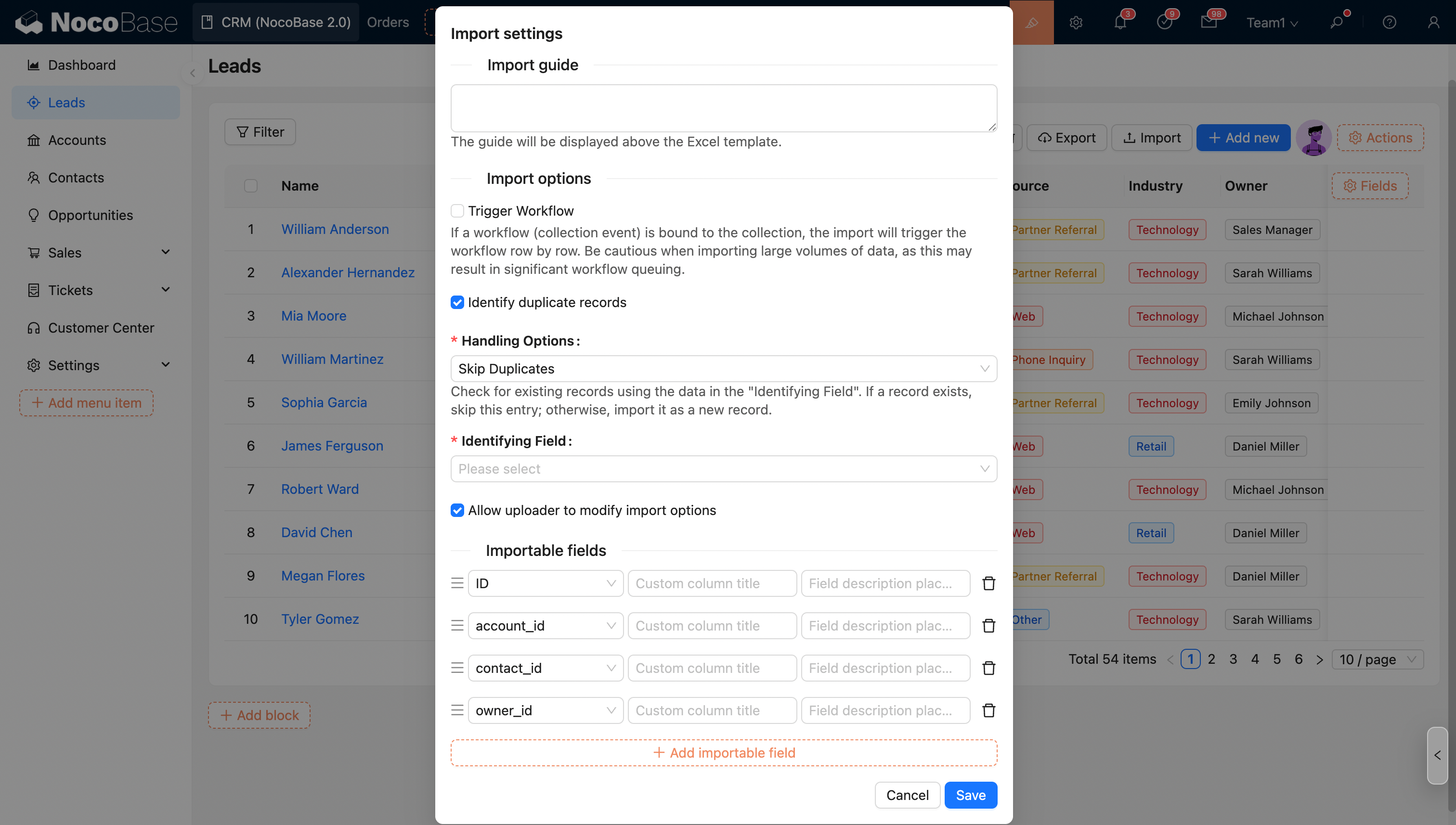
Включите этот параметр и выберите режим для определения и обработки дубликатов записей во время импорта.
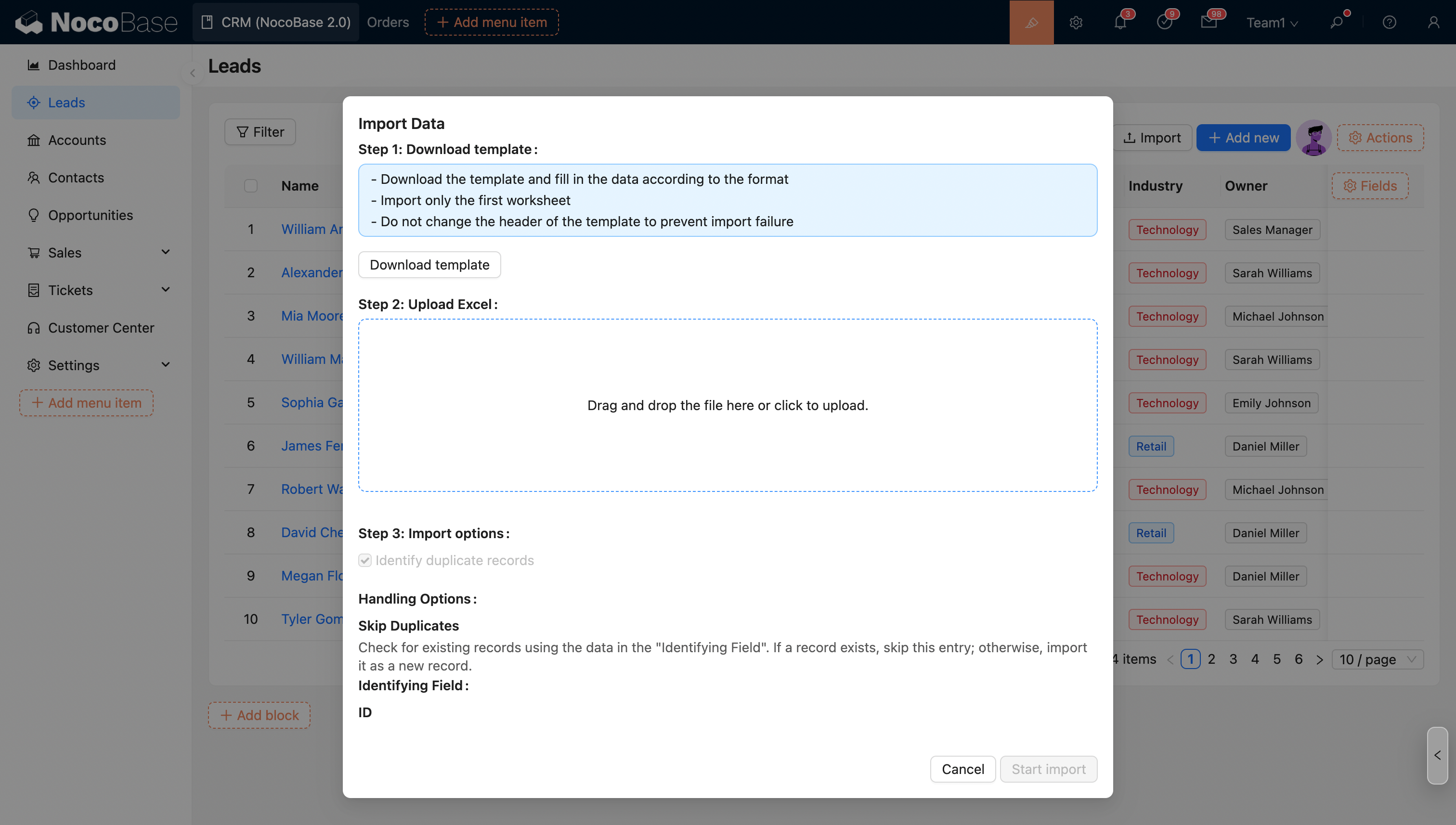
Параметры, заданные в конфигурации импорта, применяются как значения по умолчанию. Администраторы могут контролировать, разрешено ли загрузчику изменять эти параметры (кроме параметра запуска рабочего процесса).
Настройки прав загрузчика
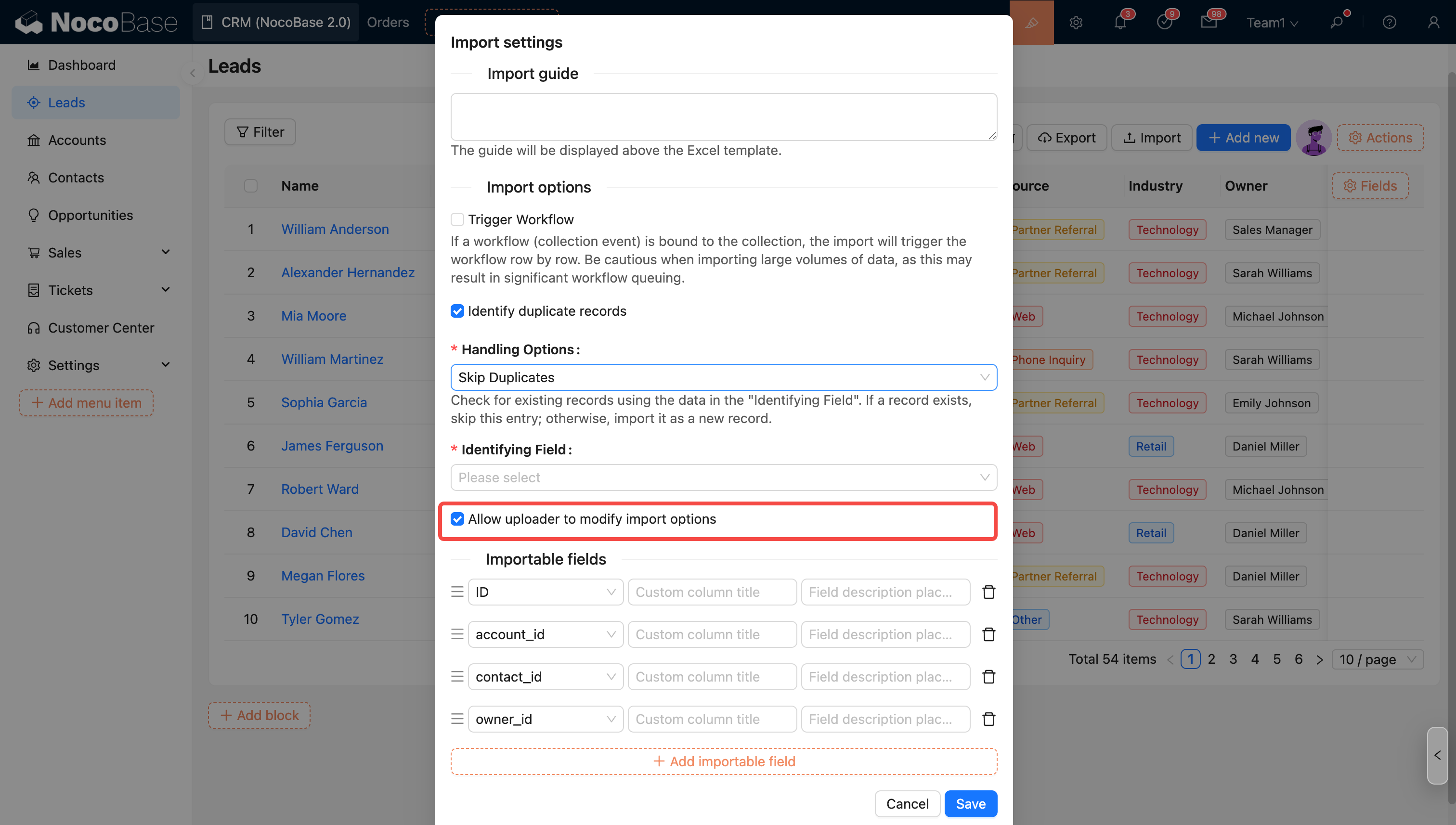
- разрешить загрузчику изменять параметры импорта;
- запретить загрузчику изменять параметры импорта.
Описание режимов
- Пропускать дубликаты: поиск существующих записей выполняется по содержимому поля «Поле идентификатора». Если запись уже существует — эта строк�а пропускается; если не существует — она импортируется как новая запись.
- Обновлять дубликаты записей: поиск выполняется по содержимому поля «Поле идентификатора». Если запись уже существует — она обновляется; если не существует — она импортируется как новая запись.
- Обновлять только дубликаты: поиск выполняется по содержимому поля «Поле идентификатора». Если запись уже существует — она обновляется; если не существует — она пропускается.
Поле идентификатора
Система определяет, является ли строка записью-дубликатом, на основе значения этого поля.
- Правила связывания: динамически показывать или скрывать кнопки;
- Кнопка редактирования: редактировать заголовок, тип и значок кнопки;