

Étendre les types de nœuds
Le type d'un nœud est essentiellement une instruction opérationnelle. Des instructions différentes représentent des opérations différentes exécutées dans le flux de travail.
Similaire aux déclencheurs, l'extension des types de nœuds se divise également en deux parties : côté serveur et côté client. Le côté serveur doit implémenter la logique des instructions enregistrées, tandis que le côté client doit fournir la configuration de l'interface pour les paramètres du nœud où se trouve l'instruction.
Côté serveur
L'instruction de nœud la plus simple
Le cœur d'une instruction est une fonction, ce qui signifie que la méthode run de la classe d'instruction doit être implémentée pour exécuter la logique de l'instruction. Vous pouvez effectuer toutes les opérations nécessaires au sein de cette fonction, telles que des opérations de base de données, des opérations de fichiers, des appels à des API tierces, etc.
Toutes les instructions doivent dériver de la classe de base Instruction. L'instruction la plus simple ne nécessite que l'implémentation d'une fonction run :
Et enregistrez cette instruction auprès du plugin de flux de travail :
La valeur de statut (status) dans l'objet de retour de l'instruction est obligatoire et doit être une valeur de la constante JOB_STATUS. Cette valeur détermine le déroulement du traitement ultérieur de ce nœud dans le flux de travail. Généralement, JOB_STATUS.RESOVLED est utilisé, indiquant que le nœud a été exécuté avec succès et que l'exécution se poursuivra vers les nœuds suivants. Si vous avez une valeur de résultat à sauvegarder à l'avance, vous pouvez également appeler la méthode processor.saveJob et retourner l'objet qu'elle renvoie. L'exécuteur générera un enregistrement du résultat d'exécution basé sur cet objet.
Valeur de résultat du nœud
Si vous avez un résultat d'exécution spécifique, en particulier des données à préparer pour les nœuds suivants, vous pouvez le retourner via la propriété result et le sauvegarder dans l'objet de tâche du nœud :
Ici, node.config est l'élément de configuration du nœud, qui peut être n'importe quelle valeur requise. Il sera sauvegardé en tant que champ de type JSON dans l'enregistrement de nœud correspondant dans la base de données.
Gestion des erreurs d'instruction
Si des exceptions peuvent survenir pendant l'exécution, vous pouvez les intercepter à l'avance et retourner un statut d'échec :
Si les exceptions prévisibles ne sont pas interceptées, le moteur de flux de travail les interceptera automatiquement et renverra un statut d'erreur pour éviter que des exceptions non gérées ne fassent planter le programme.
Nœuds asynchrones
Lorsqu'un nœud doit attendre qu'une opération externe soit terminée avant de continuer le flux de travail (comme des requêtes HTTP, des callbacks de paiement tiers, ou d'autres opérations longues ou ne renvoyant pas de résultat immédiat), la tâche doit d'abord être sauvegardée avec le statut JOB_STATUS.PENDING pour suspendre l'exécution actuelle, puis reprise via resume une fois l'opération terminée. Toute instruction utilisant une logique de suspension doit également implémenter la méthode resume ; sinon, le flux de travail ne peut pas être repris.
Le schéma d'implémentation recommandé est le suivant :
Plusieurs détails clés sont à noter :
Pourquoi appeler processor.exit() explicitement plutôt que de retourner l'objet de tâche en attente ?
return { status: PENDING } termine immédiatement la fonction run, rendant impossible l'exécution de tout code ultérieur. Appeler await processor.exit() valide uniquement la transaction et quitte le contexte de base de données, tandis que la fonction continue de s'exécuter. Cela vous permet d'await une opération longue dans le même corps de fonction, puis d'appeler resume lorsqu'elle se termine. Si vous ignorez exit() et faites directement await d'une longue opération avant de retourner, cela maintient la transaction de base de données ouverte longtemps, causant des conflits de verrous, et l'enregistrement de tâche ne sera pas persisté tant que la transaction n'est pas validée après la fin de l'opération.
Pourquoi re-interroger la tâche au lieu d'utiliser l'objet retourné par saveJob ?
L'objet retourné par saveJob est une instance de modèle en mémoire liée à la transaction d'origine. Après l'appel à processor.exit(), cette transaction a été validée et fermée. Modifier directement cette instance et appeler resume causera des anomalies d'état ORM (références de transaction obsolètes, incohérences d'état, etc.). Re-interroger depuis la base de données par id garantit d'obtenir une instance propre non liée à aucune transaction.
Pourquoi la fonction run ne retourne-t-elle rien (void) ?
processor.exit() a déjà été appelé manuellement. Lorsque l'exécuteur reçoit void, il appelle exit(true) et sort immédiatement sans traitement redondant. Si un IJob était retourné à ce stade, l'exécuteur tenterait de sauvegarder et valider à nouveau, causant des erreurs. Consultez la section sur les types de valeurs de retour de run/resume pour plus de détails.
Pour les scénarios nécessitant des callbacks externes (par exemple, résultats de paiement notifiés via webhook), la même approche s'applique : appeler processor.exit() avant d'enregistrer le callback pour s'assurer que l'enregistrement de tâche est dans la base de données avant que le système externe rappelle. Dans le callback, re-interroger la tâche par id puis appeler this.workflow.resume(job).
Pour un exemple complet en situation réelle, consultez : RequestInstruction.ts (nœud de requête HTTP, qui utilise ce schéma dans la branche de flux de travail asynchrone)
Statut du résultat du nœud
L'état d'exécution d'un nœud affecte le succès ou l'échec de l'ensemble du flux de travail. Généralement, en l'absence de branches, l'échec d'un nœud entraîne directement l'échec de l'ensemble du flux de travail. Le scénario le plus courant est que si un nœud s'exécute avec succès, il passe au nœud suivant dans la table des nœuds, jusqu'à ce qu'il n'y ait plus de nœuds suivants, auquel cas l'exécution de l'ensemble du flux de travail se termine avec un statut de succès.
Si un nœud retourne un statut d'échec pendant l'exécution, le moteur le traitera différemment selon les deux situations suivantes :
-
Le nœud qui retourne un statut d'échec se trouve dans le flux de travail principal, c'est-à-dire qu'il n'est pas dans une branche ouverte par un nœud en amont. Dans ce cas, l'ensemble du flux de travail principal est considéré comme ayant échoué et le processus se termine.
-
Le nœud qui retourne un statut d'échec se trouve dans un flux de travail de branche. Dans ce cas, la responsabilité de déterminer l'état suivant du flux de travail est transférée au nœud qui a ouvert la branche. La logique interne de ce nœud décidera de l'état du flux de travail suivant, et cette décision se propagera récursivement jusqu'au flux de travail principal.
Finalement, l'état suivant de l'ensemble du flux de travail est déterminé au niveau des nœuds du flux de travail principal. Si un nœud du flux de travail principal retourne un échec, l'ensemble du flux de travail se termine avec un statut d'échec.
Si un nœud retourne un statut « en attente » après exécution, l'ensemble du processus d'exécution sera temporairement interrompu et suspendu, en attente d'un événement défini par le nœud correspondant pour déclencher la reprise du flux de travail. Par exemple, un nœud manuel, une fois exécuté, se mettra en pause à ce nœud avec un statut « en attente », attendant une intervention humaine pour décider de l'approbation. Si le statut saisi manuellement est « approuvé », les nœuds suivants du flux de travail continueront ; sinon, il sera traité selon la logique d'échec décrite précédemment.
Pour plus de statuts de retour d'instruction, veuillez consulter la section Référence de l'API des flux de travail.
Types de valeurs de retour de run/resume et comportement de l'exécuteur
La définition complète du type de retour pour les méthodes run et resume est :
Après que l'exécuteur (Processor) appelle une instruction, il exécute une logique de traitement différente selon le type de valeur de retour. Il y a trois cas.
1. Retourner un objet de tâche IJob
C'est le cas le plus courant. Retournez un objet contenant un champ status obligatoire et un champ result facultatif. L'exécuteur le sauvegarde comme enregistrement de tâche du nœud et détermine le flux suivant selon la valeur de status :
JOB_STATUS.RESOLVED: Le nœud s'est exécuté avec succès ; continue vers le nœud suivant s'il existe, sinon le flux de travail se termineJOB_STATUS.PENDING: Le nœud entre dans un état suspendu ; le contexte d'exécution actuel s'arrête, en attente qu'un événement externe déclencheresume- Autres statuts d'échec (
FAILED,ERROR, etc.) : Propagés vers le nœud parent de la branche ou terminent directement l'ensemble du flux de travail
Ce chemin est le chemin complet de validation de transaction -- l'exécuteur sauvegarde l'enregistrement de tâche, écrit dans la base de données et valide la transaction.
Exemple : ConditionInstruction.ts (retourne un objet job directement quand il n'y a pas de branche ; voir le cas void ci-dessous quand il y a une branche)
2. Retourner null
Lorsque null est retourné, l'exécuteur appelle processor.exit() (sans argument), avec l'effet de : vider les tâches en attente actuelles dans la base de données et valider la transaction, mais sans mettre à jour le statut d'exécution global.
Cet usage est courant dans la méthode resume des nœuds de contrôle de branches : une branche a terminé et le statut de la tâche du nœud parent doit être mis à jour et sauvegardé (par exemple, enregistrer « la branche N est terminée »), mais d'autres branches sont encore en cours, et l'exécution globale doit rester en statut STARTED en attendant les branches restantes -- retourner null quitte le contexte de reprise actuel sans affecter le statut d'exécution global.
Exemple : ParallelInstruction.ts
- Ligne 117 : Le nœud parallèle s'est déjà terminé prématurément (résolu/rejeté) ; ignore les reprises de branches ultérieures et retourne
nulldirectement - Ligne 135 : Certaines branches sont encore incomplètes (
PENDING) ; sauvegarde la progression actuelle et retournenullpour continuer à attendre les autres branches
3. Retourner void (pas de retour, c'est-à-dire undefined implicite)
Lorsque void est retourné (la fonction n'a pas de déclaration de retour explicite, ou le chemin d'exécution se termine sans valeur de retour), l'exécuteur appelle processor.exit(true), avec l'effet de retourner immédiatement sans effectuer aucune opération de base de données.
Ce schéma est exclusivement pour les scénarios où l'instruction a pris en charge la planification de l'exécution : l'instruction démarre manuellement un sous-flux de travail via processor.run(), et la chaîne d'exécution du sous-flux de travail gérera les écritures en base de données et les validations de transactions lorsqu'il se terminera. L'exécuteur ne doit pas traiter à nouveau.
Exemples typiques :
- ConditionInstruction.ts#L67 : Quand une branche existe, appelle manuellement
processor.run(branchNode, savedJob)puis la fonction se termine, retournant implicitementvoid - ParallelInstruction.ts#L108 : Itère sur toutes les branches et appelle
processor.run(branch, job)pour chacune, puis la fonction se termine, retournant implicitementvoid
:::warn{title=Remarque}
Si processor.saveJob() a été appelé avant de retourner void, ces enregistrements de tâches ne seront pas écrits dans la base de données par l'exécuteur actuel. Ils sont temporairement stockés dans la liste de tâches de l'exécuteur (en mémoire) et seront vidés vers la base de données par le exit() déclenché lorsque la sous-exécution démarrée par processor.run() se termine. Par conséquent, lors de l'utilisation de ce schéma, vous devez vous assurer qu'il existe un chemin de sous-exécution qui se terminera normalement pour persister ces enregistrements. La planification des flux de travail de branche a une certaine complexité ; elle nécessite une conception soigneuse et des tests approfondis.
:::
Comparaison récapitulative des trois valeurs de retour :
En savoir plus
Pour les définitions des différents paramètres de définition des types de nœuds, consultez la section Référence de l'API des flux de travail.
Côté client
Similaire aux déclencheurs, le formulaire de configuration d'une instruction (type de nœud) doit être implémenté côté client.
L'instruction de nœud la plus simple
Toutes les instructions doivent dériver de la classe de base Instruction. Les propriétés et méthodes associées sont utilisées pour configurer et utiliser le nœud.
Par exemple, si nous devons fournir une interface de configuration pour le nœud de type chaîne de caractères numériques aléatoires (randomString) défini côté serveur, qui possède un élément de configuration digit représentant le nombre de chiffres pour le nombre aléatoire :
Ici, FieldsetLoader est une fonction qui retourne Promise<{ default: ComponentType }>, implémentant le chargement différé via import() dynamique. Le composant vers lequel elle pointe est un composant fonction React standard qui construit le formulaire à l'aide des Form.Item d'antd :
Notez que le name du champ de formulaire utilise le format de tableau imbriqué ['config', 'fieldName'], qui est la convention standard des formulaires antd.
Interfaces de configuration multiples
Un nœud peut fournir plusieurs interfaces de configuration pour différents scénarios :
-
FieldsetLoader-- Formulaire du tiroir de configuration du nœud (le plus couramment utilisé)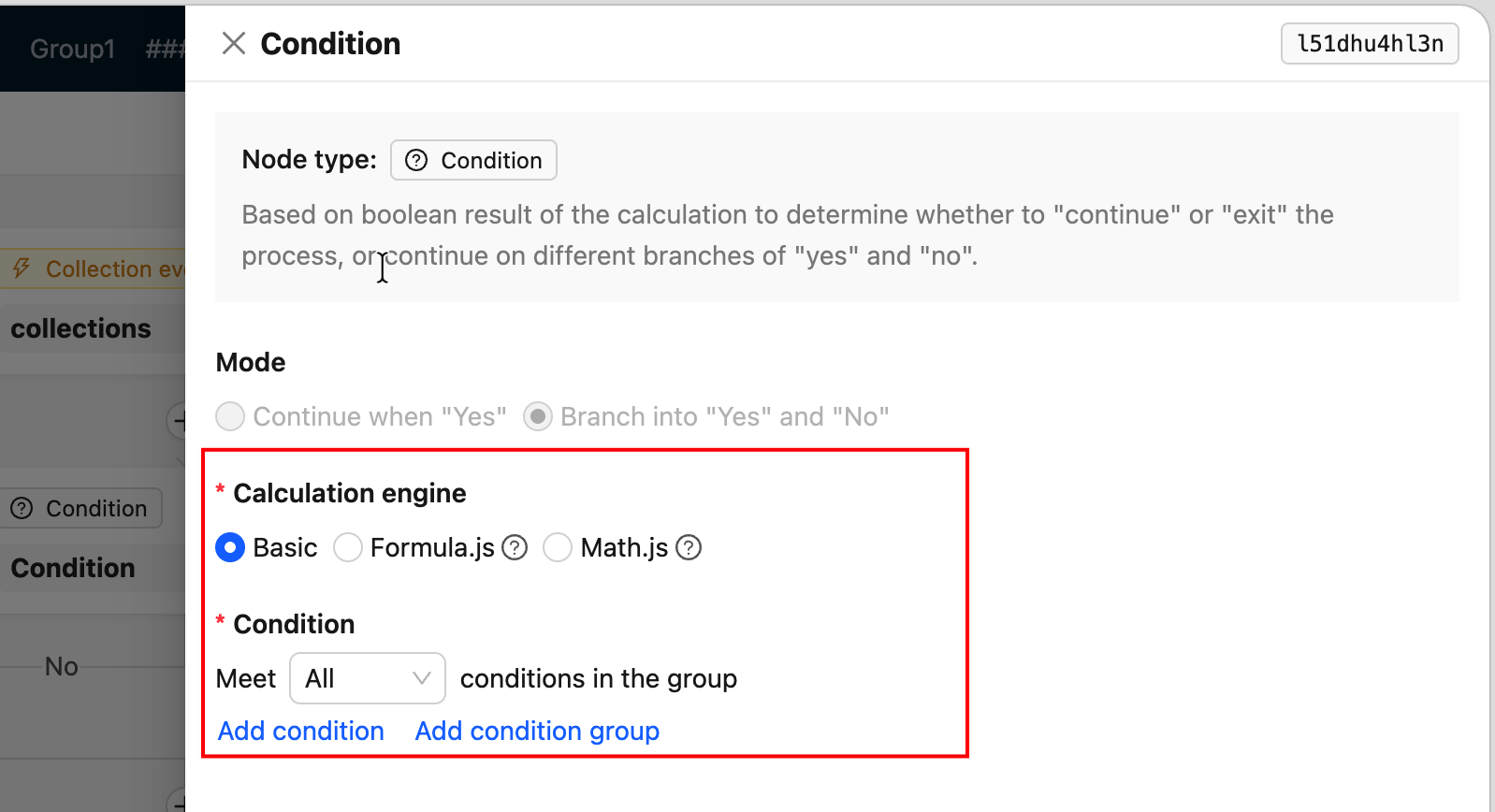
-
PresetFieldsetLoader-- Formulaire prédéfini lors de la création d'un nœud (contient généralement uniquement les champs obligatoires)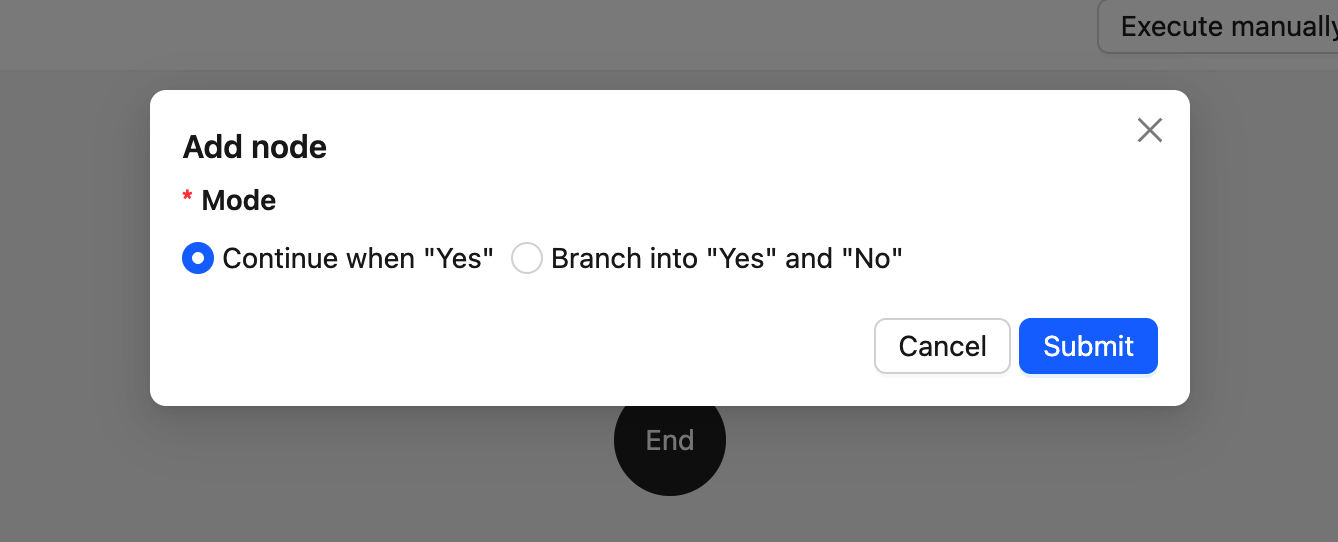
-
ComponentLoader-- Rendu personnalisé du nœud sur le canevas (utilisé pour les nœuds de branche et autres cas nécessitant un rendu spécial)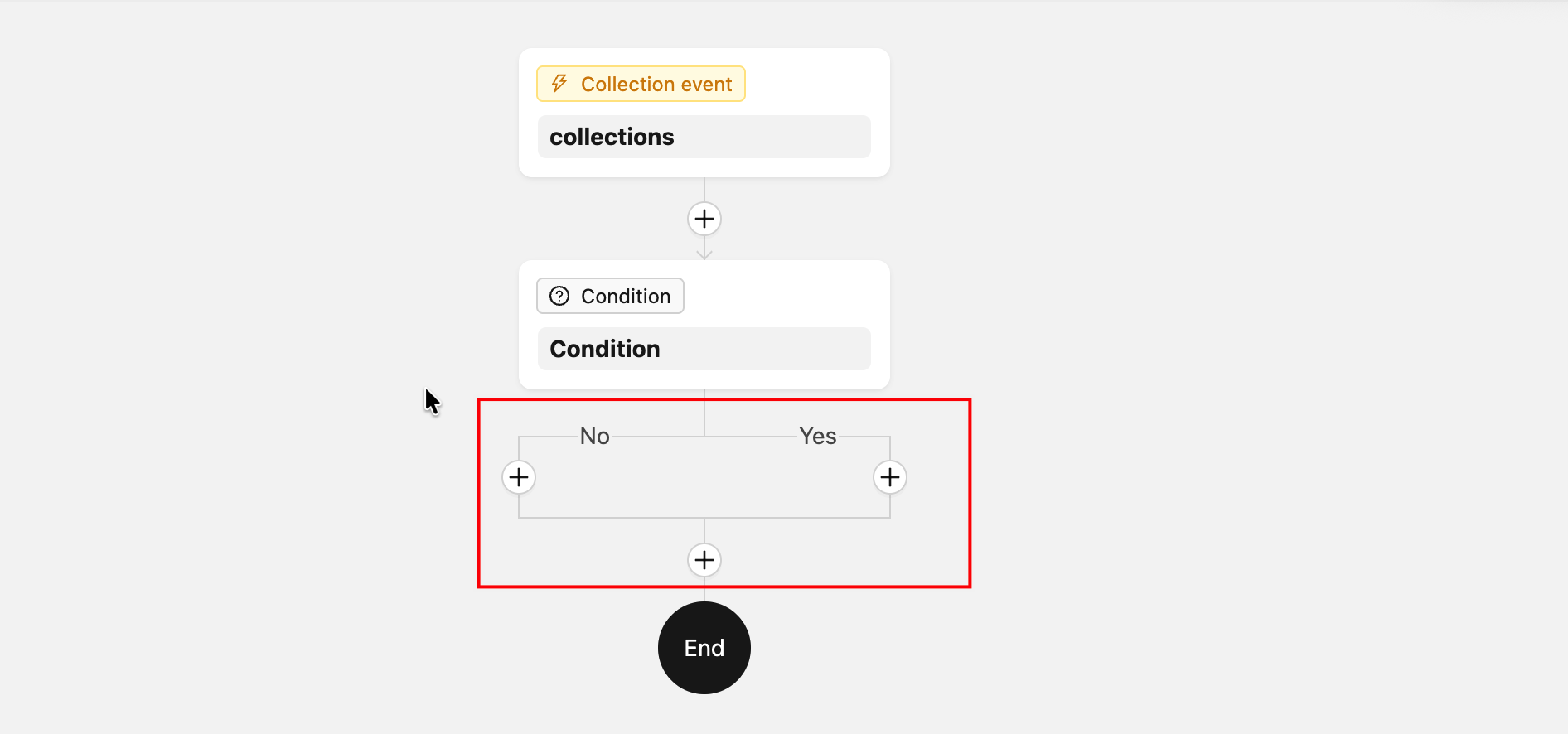
Lorsqu'un Loader doit pointer vers un export nommé (plutôt que l'export par défaut) d'un fichier, utilisez .then() pour effectuer le remappage :
Enregistrer le nœud
Enregistrez le type de nœud auprès de l'instance du plugin flux de travail au sein du plugin étendu :
L'identifiant du type de nœud enregistré côté client doit être identique à celui du côté serveur, sinon cela entraînera des erreurs.
Fournir les résultats du nœud comme variables
Vous remarquerez la méthode useVariables dans l'exemple ci-dessus. Si vous avez besoin d'utiliser le résultat du nœud (la partie result) comme variable pour les nœuds suivants, vous devez implémenter cette méthode dans la classe d'instruction dérivée et retourner un objet conforme au type VariableOption. Cet objet sert de description structurelle du résultat d'exécution du nœud, fournissant un mappage des noms de variables pour leur sélection et leur utilisation dans les nœuds suivants.
Le type VariableOption est défini comme suit :
L'élément central est la propriété value, qui représente la valeur du chemin segmenté du nom de la variable. label est utilisé pour l'affichage dans l'interface, et children est utilisé pour représenter une structure de variable à plusieurs niveaux, ce qui est utile lorsque le résultat du nœud est un objet profondément imbriqué.
Une variable utilisable est représentée en interne dans le système comme une chaîne de caractères de chemin séparée par des ., par exemple, {{$jobsMapByNodeKey.2dw92cdf.abc}}. Ici, $jobsMapByNodeKey représente l'ensemble des résultats de tous les nœuds (défini en interne, pas besoin de le gérer), 2dw92cdf est la key du nœud, et abc est une propriété personnalisée dans l'objet de résultat du nœud.
De plus, étant donné que le résultat d'un nœud peut également être une valeur simple, lors de la fourniture de variables de nœud, le premier niveau doit être la description du nœud lui-même :
C'est-à-dire que le premier niveau est la key et le titre du nœud. Par exemple, dans la référence du code du nœud de calcul, lorsque vous utilisez le résultat de ce nœud, les options de l'interface sont les suivantes :
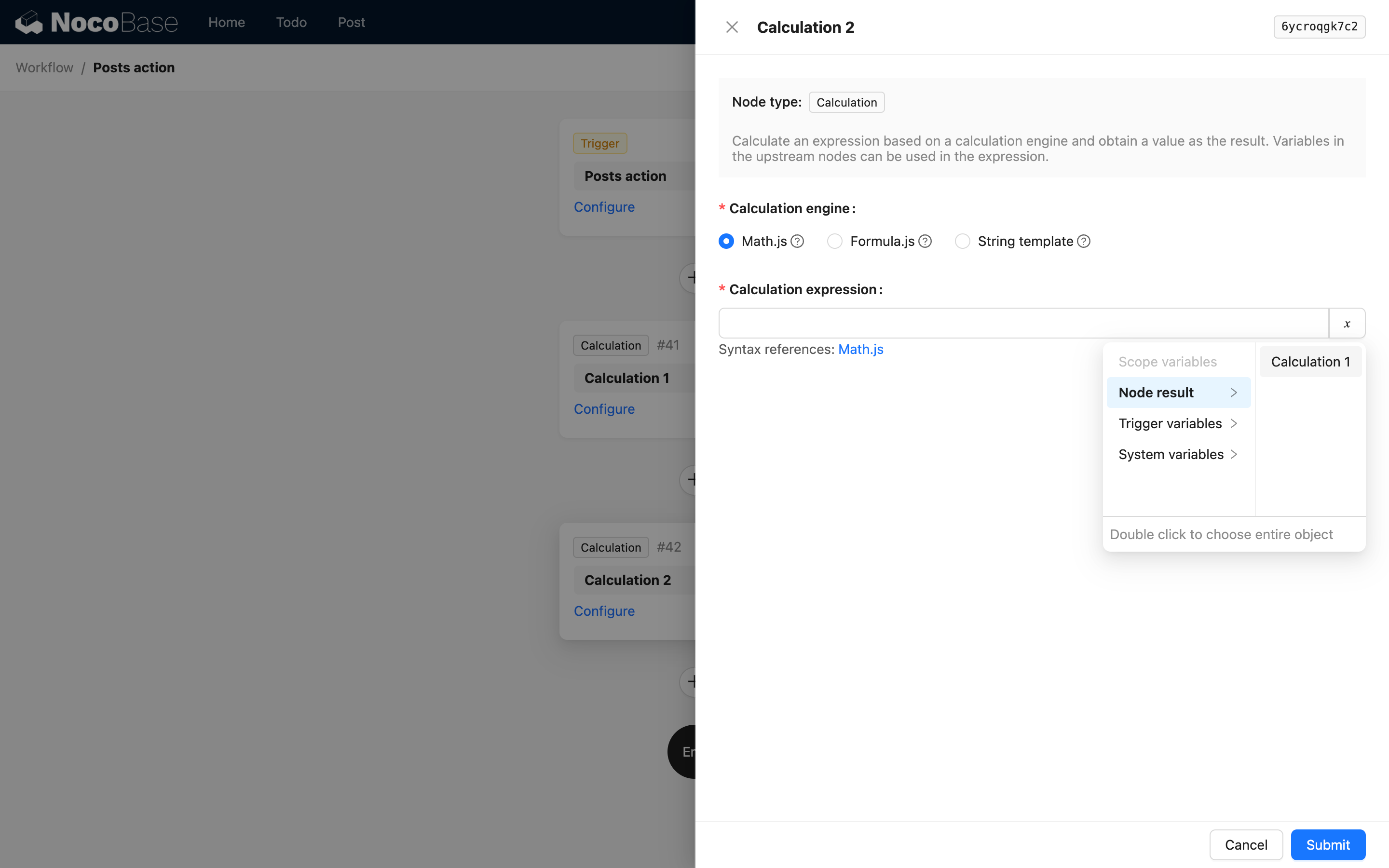
Lorsque le résultat du nœud est un objet complexe, vous pouvez utiliser children pour continuer à décrire les propriétés imbriquées. Par exemple, une instruction personnalisée pourrait retourner les données JSON suivantes :
Vous pouvez alors le retourner via la méthode useVariables comme suit :
De cette manière, dans les nœuds suivants, vous pourrez utiliser l'interface suivante pour sélectionner les variables :
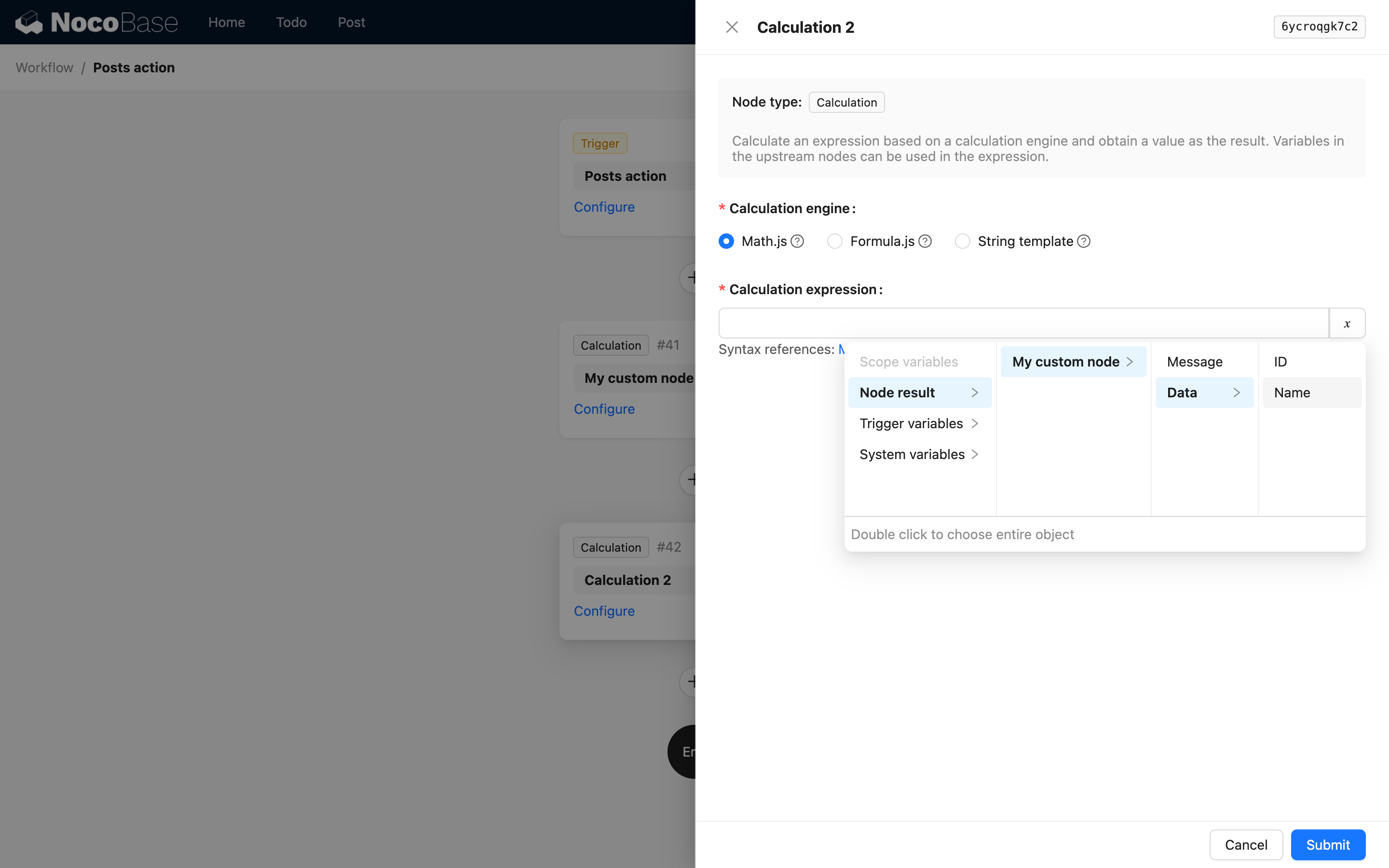
Lorsqu'une structure dans le résultat est un tableau d'objets profondément imbriqués, vous pouvez également utiliser children pour décrire le chemin, mais cela ne peut pas inclure d'indices de tableau. En effet, dans la gestion des variables des flux de travail NocoBase, la description du chemin de variable pour un tableau d'objets est automatiquement aplatie en un tableau de valeurs profondes lors de l'utilisation, et vous ne pouvez pas accéder à une valeur spécifique par son index.
Disponibilité du nœud
Par défaut, tout nœud peut être ajouté à un flux de travail. Cependant, dans certains cas, un nœud peut ne pas être applicable dans certains types de flux de travail ou de branches. Dans ces situations, vous pouvez configurer la disponibilité du nœud à l'aide de isAvailable :
La méthode isAvailable retourne true si le nœud est disponible, et false s'il ne l'est pas. Le paramètre ctx contient les informations contextuelles du nœud actuel, qui peuvent être utilisées pour déterminer sa disponibilité.
En l'absence d'exigences particulières, vous n'avez pas besoin d'implémenter la méthode isAvailable, car les nœuds sont disponibles par défaut. Le scénario de configuration le plus courant est lorsqu'un nœud peut être une opération longue et ne convient pas à une exécution dans un flux de travail synchrone. Vous pouvez utiliser la méthode isAvailable pour restreindre son utilisation. Par exemple :
En savoir plus
Pour un exemple complet en situation réelle, consultez : Code source de CalculationInstruction
Pour les définitions des différents paramètres de définition des types de nœuds, consultez la section Référence de l'API des flux de travail.
Si vous utilisiez précédemment le code côté client hérité (v1) et souhaitez migrer vers la nouvelle version v2, consultez le Guide de migration v1 vers v2.