

Расширение типов узлов
Тип узла по сути является операционной инст�рукцией. Разные инструкции представляют разные операции, выполняемые в рабочем процессе.
Как и в случае с триггерами, расширение типов узлов также делится на две части: серверную и клиентскую. На сервере нужно реализовать логику зарегистрированной инструкции, а на клиенте — предоставить интерфейсную настройку параметров узла, в котором используется эта инструкция.
Серверная часть
Самая простая инструкция узла
Ключевое содержимое инструкции — функция, то есть для выполнения логики инструкции необходимо реализовать метод run в классе инструкции. Внутри функции можно выполнять любые необходимые операции: с базой данных, файлами, сторонними API и т. д.
Все инструкции должны наследоваться от базового класса Instruction. Самая простая инструкция требует только реализации функции run:
Затем зарегистрируйте эту инструкцию в плагине рабочего процесса:
Значение статуса (status) в возвращаемом объекте инструкции обязательно и должно быть одним из значений константы JOB_STATUS. Это значение определяет дальнейший ход обработки для данного узла в рабочем процессе. Обычно используется JOB_STATUS.RESOVLED, что означает успешное выполнение узла и продолжение выполнения следующих узлов. Если есть результат, который нужно заранее сохранить, можно вызвать processor.saveJob и вернуть его возвращаемый объект. Исполнитель создаст запись результата выполнения на его основе.
Значение результата узла
Если есть конкретный результат выполнения, особенно данные для последующих узлов, его можно вернуть через свойство result и сохранить в объекте задачи узла:
Здесь node.config — это конфигурация узла, в которой могут быть любые необходимые значения. Она сохраняется как поле типа JSON в соответствующей записи узла в базе данных.
Обработка ошибок инструкции
Если при выполнении возможны исключения, их можно перехватить заранее и вернуть статус ошибки:
Если предсказуемые исключения не перехватываются, движок рабочего процесса автоматически перехватит их и вернёт статус ошибки, чтобы необработанные исключения не приводили к падению программы.
Асинхронные узлы
Если узлу нужно дождаться завершения внешней операции перед продолжением рабочего процесса (например, HTTP-запроса, колбэка от платёжной системы или другой длительной операции, результат которой не возвращается немедленно), задачу сначала нужно сохранить со статусом JOB_STATUS.PENDING, чтобы приостановить текущее выполнение, а затем возобновить его через метод resume после завершения операции. Любая инструкция, использующая логику приостановки, также должна реализовывать метод resume; иначе рабочий процесс не сможет возобновиться.
Рекомендуемая схема реализации:
Несколько важных деталей:
Почему нужно явно вызывать processor.exit(), а не возвращать объект задачи со статусом ожидания?
return { status: PENDING } немедленно завершает функцию run, поэтому код после него уже не выполнится. Вызов await processor.exit() лишь фиксирует транзакцию и выходит из контекста базы данных, тогда как сама функция продолжает выполняться. Это позволяет дождаться длительной операции в том же теле функции и вызвать resume после её завершения. Если пропустить exit() и напрямую использовать await для длительной операции перед возвратом, транзакция базы данных будет удерживаться долгое время, что может привести к конкуренции блокировок, а запись задачи не будет сохранена до фиксации транзакции после завершения операции.
Почему нужно повторно получать задачу, а не использовать объект, возвращённый saveJob?
Объект, возвращённый saveJob, — это экземпляр модели в памяти, привязанный к исходной транзакции. После вызова processor.exit() эта транзакция зафиксирована и закрыта. Прямое изменение этого экземпляра и вызов resume могут привести к некорректному состоянию ORM (устаревшим ссылкам на транзакцию, несогласованности состояния и т.д.). Повторный запрос задачи из базы данных по id гарантирует получение чистого экземпляра, не привязанного ни к ка�кой транзакции.
Почему функция run ничего не возвращает (void)?
processor.exit() уже был вызван вручную. Когда исполнитель получает void, он вызывает exit(true) и немедленно завершается без лишней обработки. Если в этот момент вернуть IJob, исполнитель попытается повторно сохранить данные и зафиксировать транзакцию, что приведёт к ошибкам. Подробнее см. раздел о типах возвращаемых значений run/resume.
Для сценариев, требующих внешних колбэков (например, результатов платежа, полученных через webhook), применяется тот же подход: вызвать processor.exit() до регистрации колбэка, чтобы запись задачи уже была сохранена в базе данных до обратного вызова внешней системы. В колбэке нужно повторно получить задачу по id, а затем вызвать this.workflow.resume(job).
Полный пример из реального проекта: RequestInstruction.ts (узел HTTP-запроса, использующий этот паттерн в ветке асинхронного рабочего процесса)
Статус результата узла
Статус выполнения узла влияет на успех или сбой всего рабочего процесса. Обычно, если ветвей нет, ошибка узла напрямую приводит к ошибке всего рабочего процесса. Наиболее типичный сценарий: если узел выполнен успешно, выполнение переходит к следующему узлу в таблице узлов, и так до тех пор, пока не останется последующих узлов; после этого весь рабочий процесс завершается успешно.
Если во время выполнения узел возвращает статус ошибки, движок обрабатывает это по-разному в следующих двух случаях:
-
Узел, вернувший ошибочный статус, находится в основном рабочем процессе, то есть не внутри подпроцесса ветви, открытого вышестоящим узлом. В этом случае весь основной рабочий процесс считается неуспешным, и процесс завершается.
-
Узел, вернувший ошибочный статус, находится внутри подпроцесса ветви. В этом случае ответственность за определение следующего состояния рабочего процесса передаётся узлу, который открыл ветвь. Его внутренняя логика определяет состояние последующего потока, и это решение рекурсивно распространяется вверх до основного рабочего процесса.
В итоге следующее состояние всего рабочего процесса определяется на уровне узлов основного потока. Если узел в основном потоке возвращает ошибку, весь рабочий процесс завершается со статусом сбоя.
Если любой узел после выполнения возвращает статус «ожидание», весь процесс выполнения временно прерывается и приостанавливается, ожидая событие, определённое соответствующим узлом, которое возобновит рабочий процесс. Например, узел «Ручная обработка» при выполнении остановится на этом узле со статусом «ожидание», ожидая ручного решения об одобрении. Если вручную введён статус одобрения, выполнение последующих узлов продолжится; иначе применится логика ошибки, описанная выше.
О других статусах возврата инструкции см. раздел «Справочник API».
Типы возвращаемых значений run/resume и поведение исполнителя
Полное определение типа возвращаемого значения методов run и resume:
После вызова инструкции исполнитель (Processor) выполняет различную логику обработки в зависимости от типа возвращаемого значения. Существует три случая.
1. Возврат объекта задачи IJob
Наиболее распространённый случай. Возвращается объект с обязательным полем status и необязательным полем result. Исполнитель сохраняет его как запись задачи узла и определяет дальнейший ход выполнения по значению status:
JOB_STATUS.RESOLVED: Узел успешно выполнен; продолжает выполнение следующего узла при его наличии, иначе рабочий процесс завершаетсяJOB_STATUS.PENDING: Узел переходит в состояние ожидания; текущий контекст выполнения останавливается, ожидая внешнего события для запускаresume- Другие статусы ошибок (
FAILED,ERRORи т.д.): Передаются родительскому узлу ветки или напрямую завершают весь рабочий процесс
Этот путь является полным путём фиксации транзакции — исполнитель сохраняет запись задачи, записывает в базу данных и фиксирует транзакцию.
Пример: ConditionInstruction.ts (возвращает объект job напрямую при отсутствии ветки; при наличии ветки см. случай void ниже)
2. Возврат null
При возврате null исполнитель вызывает processor.exit() (без аргументов), что приводит к: сбросу текущих ожидающих задач в базу данных и фиксации транзакции, но без обновления общего статуса выполнения.
Такое использование характерно для метода resume узлов управления ветками: ветка завершилась и статус задачи родительского узла необходимо обновить и сохранить (например, записать «ветка N завершена»), но другие ветки ещё выполняются, и общее выполнение должно оставаться в статусе STARTED, ожидая оставшихся веток — возврат null выходит из текущего контекста resume без влияния на общий статус выполнения.
Пример: ParallelInstruction.ts
- Строка 117: Параллельный узел уже завершён досрочно (resolved/rejected); игнорирует последующие resume веток и возвращает
nullнапрямую - Строка 135: Некоторые ветки ещё не завершены (
PENDING); со�храняет текущий прогресс и возвращаетnullдля продолжения ожидания других веток
3. Возврат void (без возврата, т.е. неявный undefined)
При возврате void (функция не содержит явного оператора return, или путь выполнения завершается без возвращаемого значения) исполнитель вызывает processor.exit(true), что приводит к немедленному возврату без выполнения каких-либо операций с базой данных.
Этот паттерн используется исключительно в сценариях, когда инструкция взяла на себя управление планированием выполнения: инструкция вручную запускает подпроцесс через processor.run(), и цепочка выполнения подпроцесса самостоятельно обработает запись в базу данных и фиксацию транзакции при завершении. Исполнитель не должен повторно обрабатывать данные.
Типичные примеры:
- ConditionInstruction.ts#L67: При наличии ветки вручную вызывает
processor.run(branchNode, savedJob), затем функция завершается, неявно возвращаяvoid - ParallelInstruction.ts#L108: Перебирает все ветки и вызывает
processor.run(branch, job)для каждой, затем функция завершается, неявно возвращаяvoid
:::warn{title=Примечание}
Если перед возвратом void был вызван processor.saveJob(), эти записи задач не будут записаны в базу данных текущим исполнителем. Они временно хранятся в списке задач исполнителя (в памяти) и будут сброшены в базу данных через exit(), вызванный при завершении подвыполнения, запущенного processor.run(). Поэтому при использовании данного паттерна необходимо убедиться, что существует путь подвыполнения, который завершается в штатном режиме для сохранения этих записей. Планирование ветвящихся рабочих процессов обладает определённой сложностью; требует тщательного проектирования и всестороннего тестирования.
:::
Сравнительная таблица трёх возвращаемых значений:
Дополнительно
Определения различных параметров для задания типов узлов см. в разделе «Справочник API».
Клиентская часть
Как и для триггеров, форму настройки для инструкции (типа узла) нужно реализовать на клиенте.
Самая простая инструкция узла
Все инструкции должны наследоваться от базового класса Instruction. Его свойства и методы используются для настройки и использования узла.
Например, если нужно предоставить интерфейс настройки для узла «строка случайного числа» (randomString), определённого выше на сервере, у которого есть параметр digit (количество цифр):
Здесь FieldsetLoader — функция, возвращающая Promise<{ default: ComponentType }>, реализующая отложенную загрузку через динамический import(). Компонент, на который она указывает, — стандартный функциональный React-компонент, строящий форму с помощью Form.Item из antd:
Обратите внимание, что поле формы name использует формат вложенного массива ['config', 'fieldName'] — стандартное соглашение antd Form.
Несколько интерфейсов настройки
Узел может предоставлять несколько интерфейсов настройки для различных сценариев:
-
FieldsetLoader— форма настройки узла в панели (наиболее часто используется)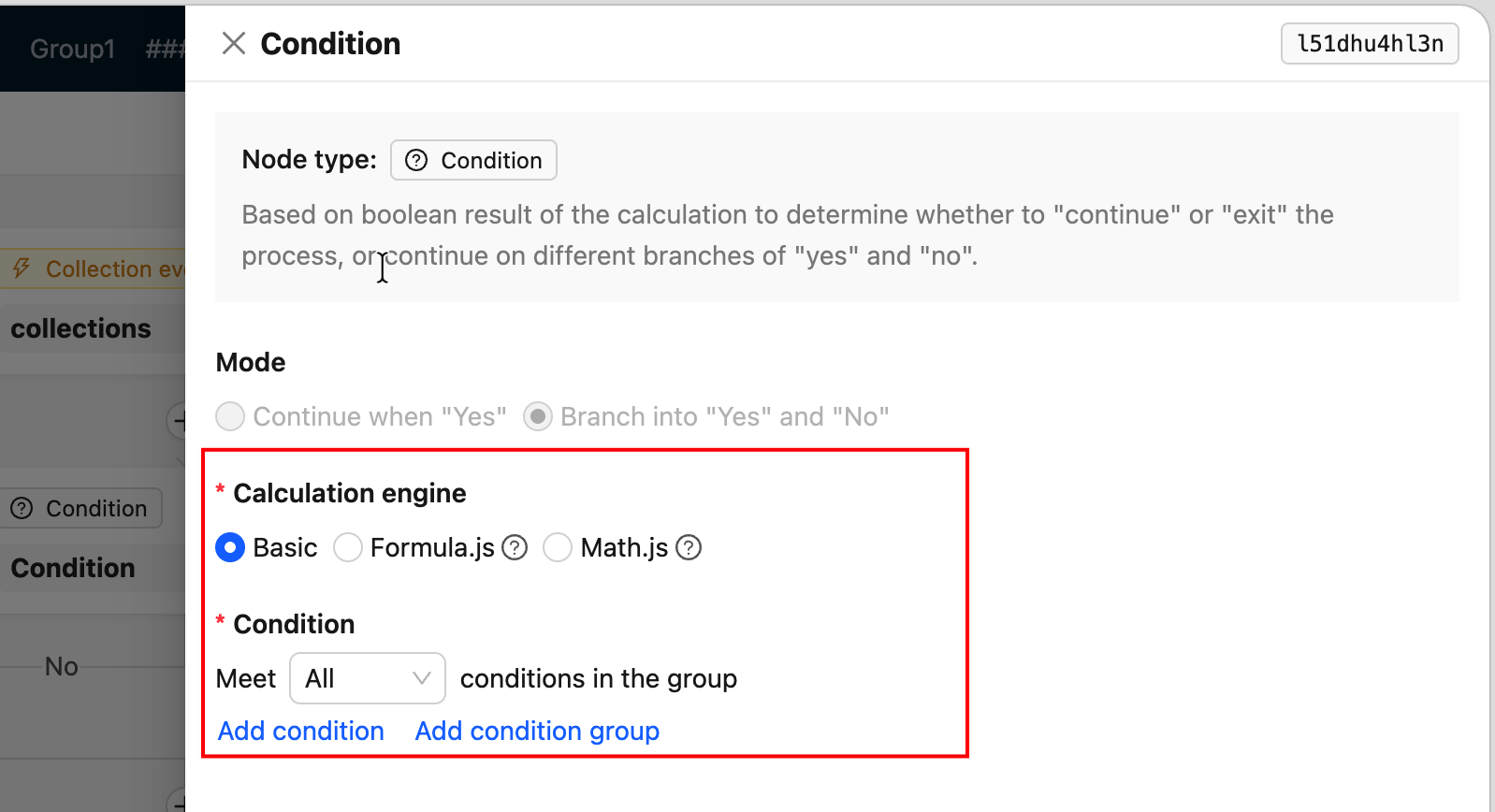
-
PresetFieldsetLoader— предустановленная форма при создании узла (обычно содержит только обязательные поля)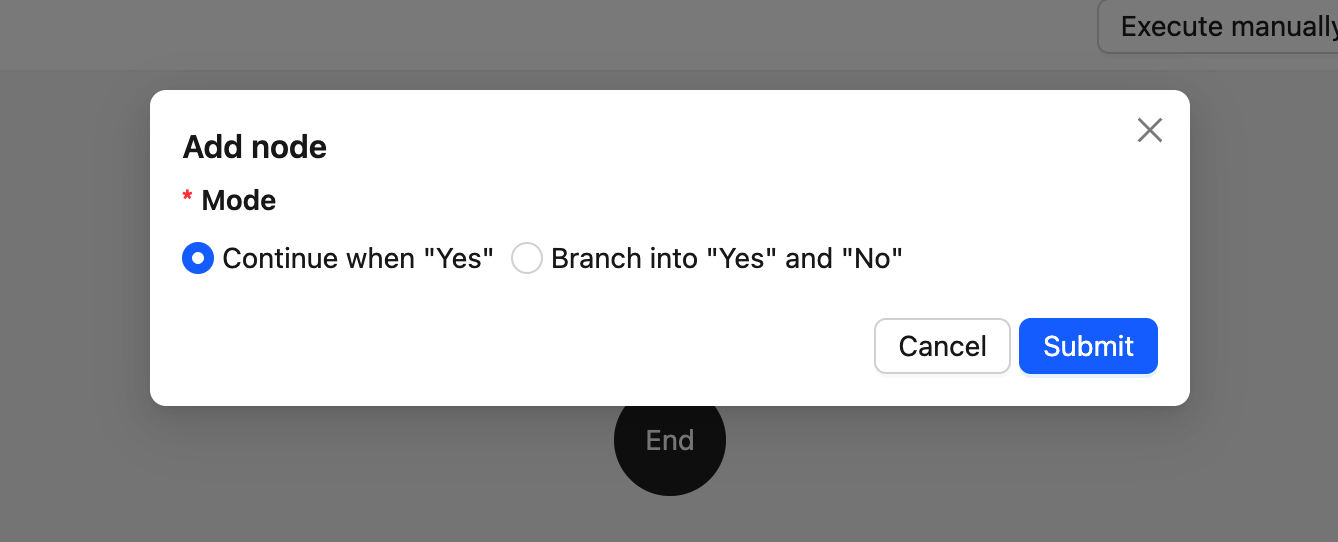
-
ComponentLoader— пользовательский рендеринг узла на холсте (используется для узлов с ветвлением и других случаев, требующих особого отображения)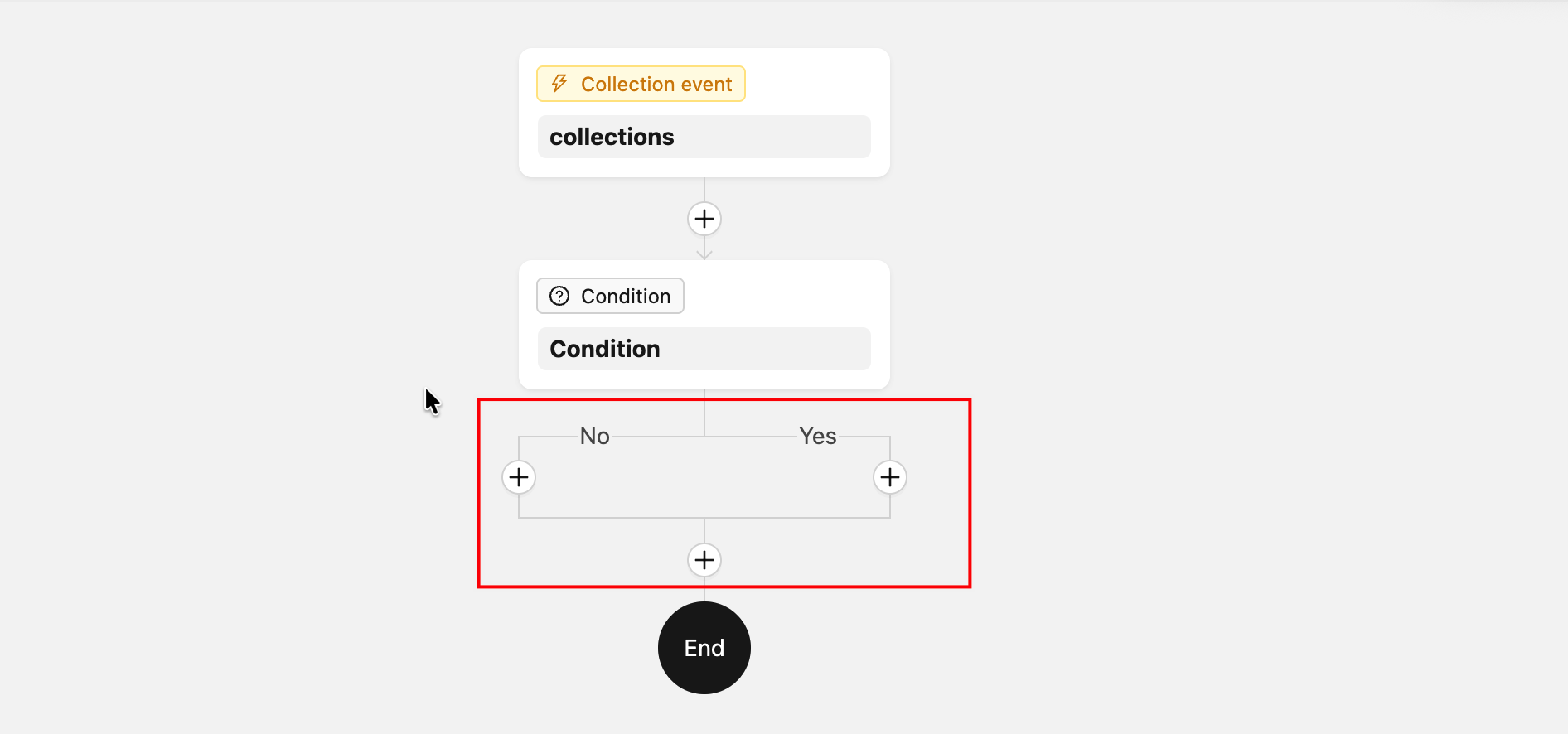
Когда Loader должен указывать на именованный экспорт (а не экспорт по умолчанию) файла, используйте .then() для переназначения:
Регистрация узла
Зарегистрируйте тип узла в экземпляре плагина рабочего процесса внутри расширяющего плагина:
Идентификатор типа узла, зарегистрированный на клиенте, должен совпадать с идентификатором на сервере, иначе возникнут ошибки.
Предоставление результатов узла как переменных
В приведённом выше примере используется метод useVariables. Если нужно использовать результат узла (часть result) как переменную в последующих узлах, нужно реализовать эт�от метод в унаследованном классе инструкции и вернуть объект, соответствующий типу VariableOption. Этот объект задаёт структурное описание результата выполнения узла и сопоставление имён переменных для выбора и использования в следующих узлах.
Тип VariableOption определяется так:
Ключевым является свойство value: это сегментированный путь имени переменной. Свойство label задаёт подпись в интерфейсе, а children — многоуровневую структуру переменных, когда результат узла — глубоко вложенный объект.
Используемая переменная внутри системы задаётся как строка шаблона пути, разделённого точкой, например {{$jobsMapByNodeKey.2dw92cdf.abc}}. Здесь $jobsMapByNodeKey — набор результатов всех узлов (внутреннее определение, отдельно обрабатывать не нужно), 2dw92cdf — key узла, а abc — пользовательское свойство в объекте результата узла.
Кроме того, поскольку результат узла может быть и простым значением, при предоставлении переменных узла первый уровень обязательно должен быть описанием самого узла:
То есть первый уровень — это key и заголовок узла. Например, в исходном коде узла «Вычисление» при использовании результата узла «Вычисление» в интерфейсе отображаются такие варианты:
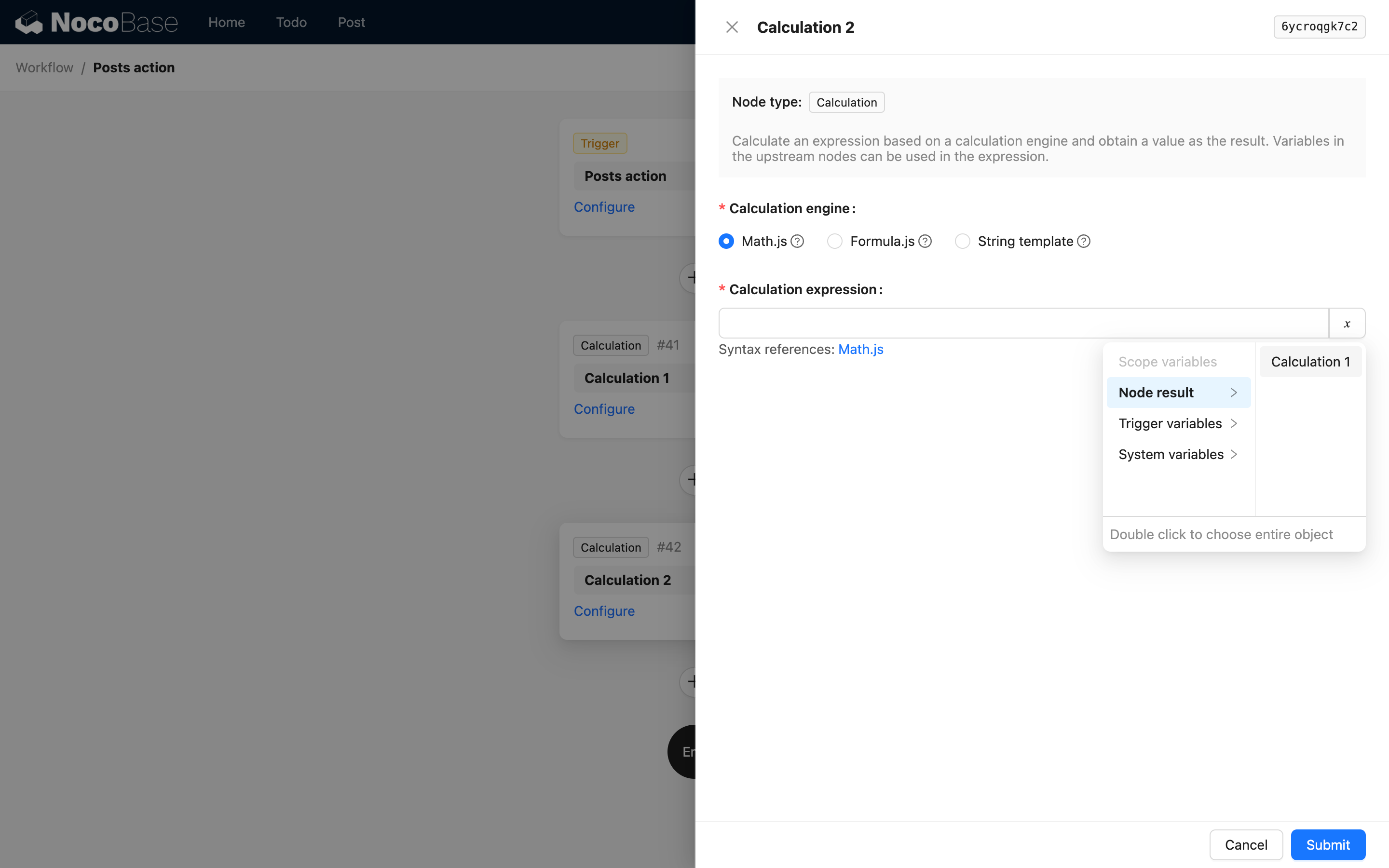
Когда результат узла — сложный объект, можно использовать children для описания вложенных свойств. Например, пользовательская инструкция может возвращать такие JSON-данные:
Тогда через метод useVariables можно вернуть описание так:
После этого в последующих узлах можно выбирать переменные через такой интерфейс:
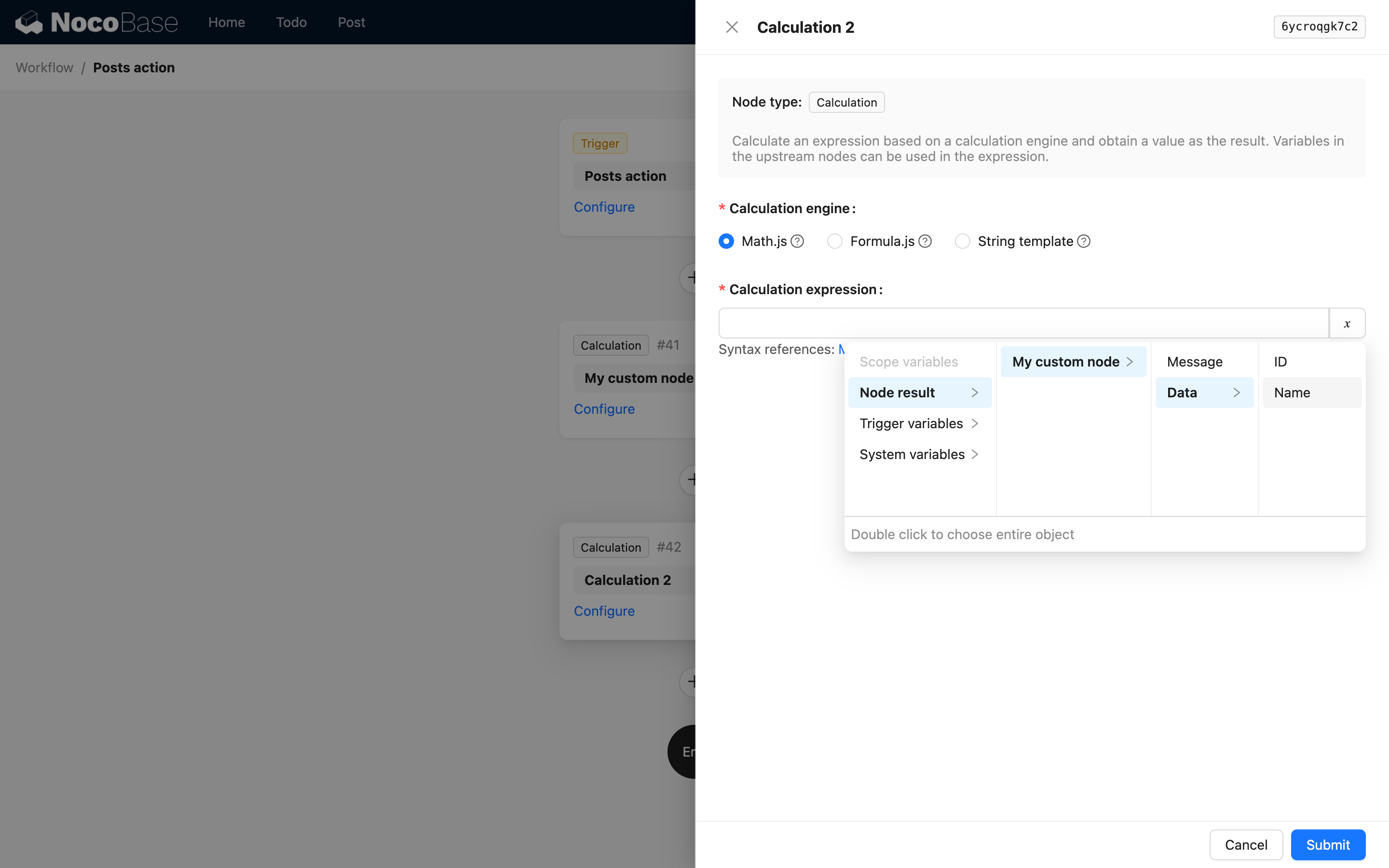
Когда структура результата является массивом глубоко вложенных объектов, путь также можно описывать через children, но без индексов массива. Это связано с тем, что в обработке переменных рабочего процесса NocoBase описание пути для массива объектов автоматически разворачивается в массив вложенных значений, и обратиться к конкретному значению по индексу нельзя.
До�ступность узла
По умолчанию в рабочий процесс можно добавить любой узел. Однако в некоторых случаях узел может быть неприменим для определённых типов рабочего процесса или ветвей. Тогда можно задать доступность узла через isAvailable:
Метод isAvailable возвращает true, если узел доступен, и false, если недоступен. Параметр ctx содержит контекст текущего узла для определения доступности.
Если особых требований нет, метод isAvailable можно не реализовывать: узлы по умолчанию доступны. Частый сценарий — узел выполняет длительную операцию и не подходит для синхронного рабочего процесса; тогда ограничение задают через isAvailable. Например:
Дополнительно
Полный пример из реального проекта: исходный код CalculationInstruction
Описание параметров типов узлов см. в разделе Справочник API.
Если вы ранее использовали устаревший клиентский код (v1) и хотите перейти на новую версию v2, обратитесь к Руководству по миграции с v1 на v2.