

Knotentypen erweitern
Der Typ eines Knotens ist im Wesentlichen eine Betriebsanweisung. Verschiedene Anweisungen repräsentieren unterschiedliche Operationen, die im Workflow ausgeführt werden.
Ähnlich wie bei Triggern gliedert sich die Erweiterung von Knotentypen in zwei Teile: serverseitig und clientseitig. Der Server muss die Logik für die registrierte Anweisung implementieren, während der Client die Oberflächenkonfiguration für die Parameter des Knotens bereitstellen muss, in dem sich die Anweisung befindet.
Serverseitig
Die einfachste Knoten-Anweisung
Der Kerninhalt einer Anweisung ist eine Funktion, das heißt, die run-Methode in der Anweisungsklasse muss implementiert werden, um die Logik der Anweisung auszuführen. Innerhalb der Funktion können beliebige erforderliche Operationen ausgeführt werden, wie z. B. Datenbankoperationen, Dateivorgänge oder das Aufrufen von Drittanbieter-APIs.
Alle Anweisungen müssen von der Basisklasse Instruction abgeleitet werden. Die einfachste Anweisung erfordert lediglich die Implementierung einer run-Funktion:
Und registrieren Sie diese Anweisung im Workflow-Plugin:
Der Statuswert (status) im Rückgabeobjekt der Anweisung ist obligatorisch und muss ein Wert aus der Konstante JOB_STATUS sein. Dieser Wert bestimmt den weiteren Verlauf der Verarbeitung für diesen Knoten im Workflow. Normalerweise wird JOB_STATUS.RESOVLED verwendet, was bedeutet, dass der Knoten erfolgreich ausgeführt wurde und die Ausführung mit den nachfolgenden Knoten fortgesetzt wird. Wenn ein Ergebniswert vorab gespeichert werden muss, können Sie auch die Methode processor.saveJob aufrufen und deren Rückgabeobjekt zurückgeben. Der Executor generiert basierend auf diesem Objekt einen Ausführungsergebnisdatensatz.
Knoten-Rückgabewert
Wenn ein spezifisches Ausführungsergebnis vorliegt, insbesondere Daten, die für nachfolgende Knoten vorbereitet werden, kann dieses über die result-Eigenschaft zurückgegeben und im Job-Objekt des Knotens gespeichert werden:
Dabei ist node.config die Konfigurationseinstellung des Knotens, die beliebige erforderliche Werte enthalten kann. Sie wird als Feld vom Typ JSON im entsprechenden Knotendatensatz in der Datenbank gespeichert.
Fehlerbehandlung von Anweisungen
Wenn während der Ausführung Ausnahmen auftreten können, können Sie diese vorab abfangen und einen Fehlerstatus zurückgeben:
Wenn vorhersehbare Ausnahmen nicht abgefangen werden, fängt die Workflow-Engine diese automatisch ab und gibt einen Fehlerstatus zurück, um zu verhindern, dass nicht abgefangene Ausnahmen zum Absturz des Programms führen.
Asynchrone Knoten
Wenn ein Knoten auf den Abschluss einer externen Operation warten muss, bevor der Workflow fortgesetzt werden kann (z. B. HTTP-Anfragen, Drittanbieter-Zahlungs-Callbacks oder andere zeitaufwändige bzw. nicht sofort zurückgebende Operationen), sollte der Task zunächst mit dem Status JOB_STATUS.PENDING gespeichert werden, um die aktuelle Ausführung anzuhalten, und anschließend nach Abschluss der Operation über resume fortgesetzt werden. Jede Anweisung, die Anhaltelogik verwendet, muss auch die resume-Methode implementieren; andernfalls kann der Workflow nicht fortgesetzt werden.
Das empfohlene Implementierungsmuster lautet wie folgt:
Es gibt mehrere wichtige Details zu beachten:
Warum processor.exit() explizit aufrufen, anstatt das ausstehende Task-Objekt zurückzugeben?
return { status: PENDING } beendet die run-Funktion sofort, was es unmöglich macht, danach noch Code auszuführen. Der Aufruf von await processor.exit() schreibt lediglich die Transaktion fest und beendet den Datenbankkontext, während die Funktion selbst weiter ausgeführt wird. Dadurch können Sie im selben Funktionskörper eine zeitaufwändige Operation mit await abwarten und anschließend resume aufrufen, wenn sie abgeschlossen ist. Wenn Sie exit() überspringen und direkt eine lange Operation mit await abwarten, bevor Sie zurückgeben, hält dies sowohl die Datenbanktransaktion lange offen (was zu Sperrkonflikten führt) als auch wird der Task-Datensatz erst nach Abschluss der Operation beim Transaction-Commit persistiert.
Warum den Task erneut abfragen, anstatt das von saveJob zurückgegebene Objekt zu verwenden?
Das von saveJob zurückgegebene Objekt ist eine In-Memory-Modellinstanz, die an die ursprüngliche Transaktion gebunden ist. Nachdem processor.exit() aufgerufen wurde, wurde diese Transaktion committet und geschlossen. Das direkte Ändern dieser Instanz und der Aufruf von resume führt zu ORM-Zustandsanomalien (veraltete Transaktionsreferenzen, Zustandsinkonsistenzen usw.). Die erneute Abfrage aus der Datenbank über id stellt sicher, dass eine saubere, an keine Transaktion gebundene Instanz vorliegt.
Warum gibt die run-Funktion nichts zurück (void)?
processor.exit() wurde bereits manuell aufgerufen. Wenn der Executor void empfängt, ruft er exit(true) auf und beendet sofort ohne redundante Verarbeitung. Würde an dieser Stelle ein IJob zurückgegeben, würde der Executor versuchen, erneut zu speichern und zu committen, was zu Fehlern führt. Weitere Details finden Sie im Abschnitt zu den Rückgabewerttypen von run/resume.
Für Szenarien, die externe Callbacks erfordern (z. B. Zahlungsergebnisse, die per Webhook gemeldet werden), gilt derselbe Ansatz: Rufen Sie processor.exit() auf, bevor Sie den Callback registrieren, um sicherzustellen, dass der Task-Datensatz in der Datenbank ist, bevor das externe System zurückruft. Im Callback fragen Sie den Task erneut über id ab und rufen dann this.workflow.resume(job) auf.
Ein vollständiges Praxisbeispiel finden Sie unter: RequestInstruction.ts (HTTP-Anfrage-Knoten, der dieses Muster im asynchronen Workflow-Zweig verwendet)
Knoten-Ergebnisstatus
Der Ausführungsstatus eines Knotens beeinflusst den Erfolg oder Misserfolg des gesamten Workflows. Normalerweise führt das Scheitern eines Knotens ohne Verzweigungen direkt zum Scheitern des gesamten Workflows. Das gängigste Szenario ist, dass ein Knoten bei erfolgreicher Ausführung zum nächsten Knoten in der Knotentabelle übergeht, bis keine weiteren Knoten mehr folgen, woraufhin der gesamte Workflow erfolgreich abgeschlossen wird.
Wenn ein Knoten während der Ausführung einen fehlgeschlagenen Ausführungsstatus zurückgibt, verarbeitet die Engine dies je nach den folgenden zwei Situationen unterschiedlich:
-
Befindet sich der Knoten, der einen Fehlerstatus zurückgibt, im Haupt-Workflow, d. h. nicht innerhalb eines von einem vorgelagerten Knoten geöffneten Verzweigungs-Workflows, wird der gesamte Haupt-Workflow als fehlgeschlagen bewertet und der Prozess beendet.
-
Befindet sich der Knoten, der einen Fehlerstatus zurückgibt, innerhalb eines Verzweigungs-Workflows, wird die Verantwortung für die Bestimmung des nächsten Workflow-Status an den Knoten übergeben, der die Verzweigung geöffnet hat. Die interne Logik dieses Knotens entscheidet über den Status des nachfolgenden Workflows, und diese Entscheidung wird rekursiv auf den Haupt-Workflow übertragen.
Letztendlich wird der nächste Status des gesamten Workflows an den Knoten des Haupt-Workflows bestimmt. Wenn ein Knoten im Haupt-Workflow einen Fehler zurückgibt, endet der gesamte Workflow mit einem Fehlerstatus.
Wenn ein Knoten nach der Ausführung den Status "angehalten" zurückgibt, wird der gesamte Ausführungsprozess vorübergehend unterbrochen und angehalten, um auf ein vom entsprechenden Knoten definiertes Ereignis zu warten, das die Fortsetzung der Workflow-Ausführung auslöst. Beispielsweise pausiert der manuelle Knoten nach der Ausführung mit dem Status "angehalten" an diesem Knoten und wartet auf eine manuelle Intervention, um zu entscheiden, ob genehmigt wird. Wenn der manuell eingegebene Status "Genehmigung" ist, werden die nachfolgenden Workflow-Knoten fortgesetzt; andernfalls wird er gemäß der zuvor beschriebenen Fehlerlogik behandelt.
Weitere Informationen zu den Rückgabestatus von Anweisungen finden Sie im Abschnitt Workflow-API-Referenz.
Rückgabewerttypen von run/resume und Verhalten des Executors
Die vollständige Rückgabetypendefinition für die Methoden run und resume lautet:
Nachdem der Executor (Processor) eine Anweisung aufgerufen hat, führt er je nach Rückgabewerttyp unterschiedliche Verarbeitungslogik aus. Es gibt drei Fälle.
1. Rückgabe eines Task-Objekts IJob
Dies ist der häufigste Fall. Es wird ein Objekt zurückgegeben, das ein obligatorisches status-Feld und ein optionales result-Feld enthält. Der Executor speichert es als Task-Datensatz des Knotens und bestimmt den weiteren Verlauf basierend auf dem status-Wert:
JOB_STATUS.RESOLVED: Knoten erfolgreich ausgeführt; fährt mit dem nächsten Knoten fort, falls vorhanden, andernfalls endet der WorkflowJOB_STATUS.PENDING: Knoten tritt in einen angehaltenen Zustand ein; der aktuelle Ausführungskontext stoppt und wartet auf ein externes Ereignis, dasresumeauslöst- Andere Fehlerstatus (
FAILED,ERRORusw.): Werden an den übergeordneten Verzweigungsknoten weitergegeben oder beenden den gesamten Workflow direkt
Dieser Pfad ist der vollständige Transaktions-Commit-Pfad -- der Executor speichert den Task-Datensatz, schreibt in die Datenbank und committet die Transaktion.
Beispiel: ConditionInstruction.ts (gibt ein job-Objekt direkt zurück, wenn keine Verzweigung vorhanden ist; siehe den void-Fall weiter unten bei Verzweigungen)
2. Rückgabe von null
Wenn null zurückgegeben wird, ruft der Executor processor.exit() (ohne Argument) auf, mit der Wirkung: Ausstehende Tasks werden in die Datenbank geschrieben und die Transaktion wird committet, aber der Gesamtausführungsstatus wird nicht aktualisiert.
Diese Verwendung ist in der resume-Methode von Verzweigungssteuerungsknoten üblich: Eine Verzweigung wurde abgeschlossen und der Task-Status des übergeordneten Knotens muss aktualisiert und gespeichert werden (z. B. "Zweig N wurde abgeschlossen"), aber andere Zweige laufen noch, und die Gesamtausführung soll im Status STARTED bleiben und auf die verbleibenden Zweige warten -- die Rückgabe von null beendet den aktuellen Resume-Kontext, ohne den Gesamtausführungsstatus zu beeinflussen.
Beispiel: ParallelInstruction.ts
- Zeile 117: Der parallele Knoten hat bereits frühzeitig abgeschlossen (resolved/rejected); ignoriert nachfolgende Zweig-Resumes und gibt direkt
nullzurück - Zeile 135: Einige Zweige sind noch nicht abgeschlossen (
PENDING); speichert den aktuellen Fortschritt und gibtnullzurück, um weiter auf andere Zweige zu warten
3. Rückgabe von void (kein Rückgabewert, d. h. implizites undefined)
Wenn void zurückgegeben wird (die Funktion hat keine explizite Return-Anweisung oder der Ausführungspfad endet ohne Rückgabewert), ruft der Executor processor.exit(true) auf, mit der Wirkung: Sofortige Rückkehr ohne Datenbankoperationen.
Dieses Muster ist ausschließlich für Szenarien, in denen die Anweisung die Ausführungsplanung übernommen hat: Die Anweisung startet manuell einen Sub-Workflow über processor.run(), und die Ausführungskette des Sub-Workflows übernimmt Datenbankschreibvorgänge und Transaktions-Commits bei Abschluss. Der Executor sollte nicht erneut verarbeiten.
Typische Beispiele:
- ConditionInstruction.ts#L67: Wenn eine Verzweigung vorhanden ist, wird
processor.run(branchNode, savedJob)manuell aufgerufen, dann endet die Funktion und gibt implizitvoidzurück - ParallelInstruction.ts#L108: Iteriert durch alle Zweige und ruft
processor.run(branch, job)für jeden auf, dann endet die Funktion und gibt implizitvoidzurück
:::warn{title=Hinweis}
Wenn processor.saveJob() vor der Rückgabe von void aufgerufen wurde, werden diese Task-Datensätze nicht vom aktuellen Executor in die Datenbank geschrieben. Sie werden vorübergehend in der Task-Liste des Executors (im Arbeitsspeicher) gespeichert und beim exit() in die Datenbank geschrieben, das ausgelöst wird, wenn die von processor.run() gestartete Sub-Ausführung abgeschlossen wird. Daher müssen Sie bei Verwendung dieses Musters sicherstellen, dass es einen Sub-Ausführungspfad gibt, der normal abgeschlossen wird, um diese Datensätze zu persistieren. Die Planung von Verzweigungs-Workflows hat eine gewisse Komplexität; sie erfordert sorgfältiges Design und umfassende Tests.
:::
Zusammenfassende Gegenüberstellung der drei Rückgabewerte:
Weitere Informationen
Die Definitionen der verschiedenen Parameter zur Definition von Knotentypen finden Sie im Abschnitt Workflow-API-Referenz.
Clientseitig
Ähnlich wie bei Triggern muss das Konfigurationsformular für eine Anweisung (Knotentyp) clientseitig implementiert werden.
Die einfachste Knoten-Anweisung
Alle Anweisungen müssen von der Basisklasse Instruction abgeleitet werden. Die zugehörigen Eigenschaften und Methoden dienen der Konfiguration und Nutzung des Knotens.
Wenn wir beispielsweise eine Konfigurationsoberfläche für den oben serverseitig definierten Knotentyp "Zufallszahlzeichenkette" (randomString) bereitstellen möchten, der eine Konfigurationseinstellung digit für die Anzahl der Ziffern der Zufallszahl enthält:
Dabei ist FieldsetLoader eine Funktion, die Promise<{ default: ComponentType }> zurückgibt und über dynamisches import() Lazy Loading implementiert. Die Komponente, auf die sie verweist, ist eine Standard-React-Funktionskomponente, die das Formular mit antd's Form.Item aufbaut:
Beachten Sie, dass der name des Formularfelds das verschachtelte Array-Format ['config', 'fieldName'] verwendet, was der antd-Form-Standardkonvention entspricht.
Mehrere Konfigurationsoberflächen
Ein Knoten kann mehrere Konfigurationsoberflächen für verschiedene Szenarien bereitstellen:
-
FieldsetLoader-- Konfigurationsformular im Knoten-Drawer (am häufigsten verwendet)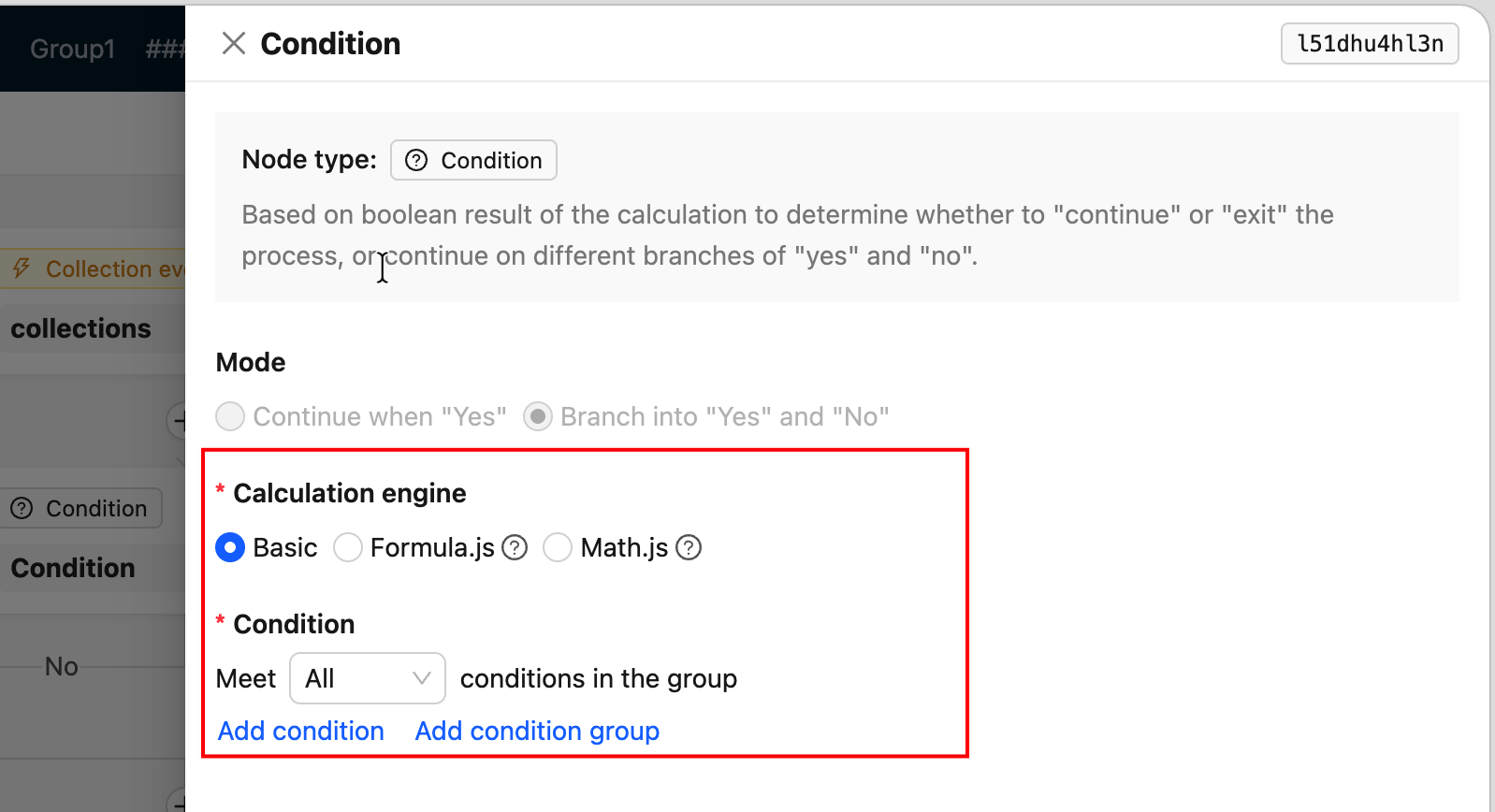
-
PresetFieldsetLoader-- Voreinstellungsformular beim Erstellen eines Knotens (enthält normalerweise nur Pflichtfelder)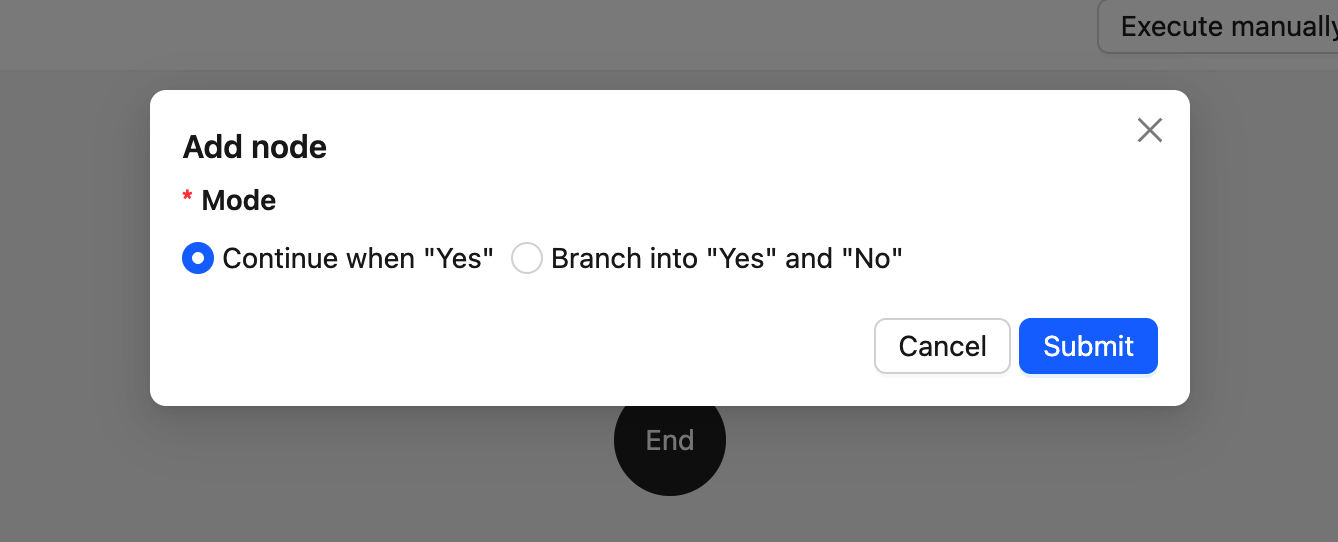
-
ComponentLoader-- Benutzerdefiniertes Knoten-Rendering auf der Zeichenfläche (wird für Verzweigungsknoten und andere Fälle verwendet, die ein spezielles Rendering erfordern)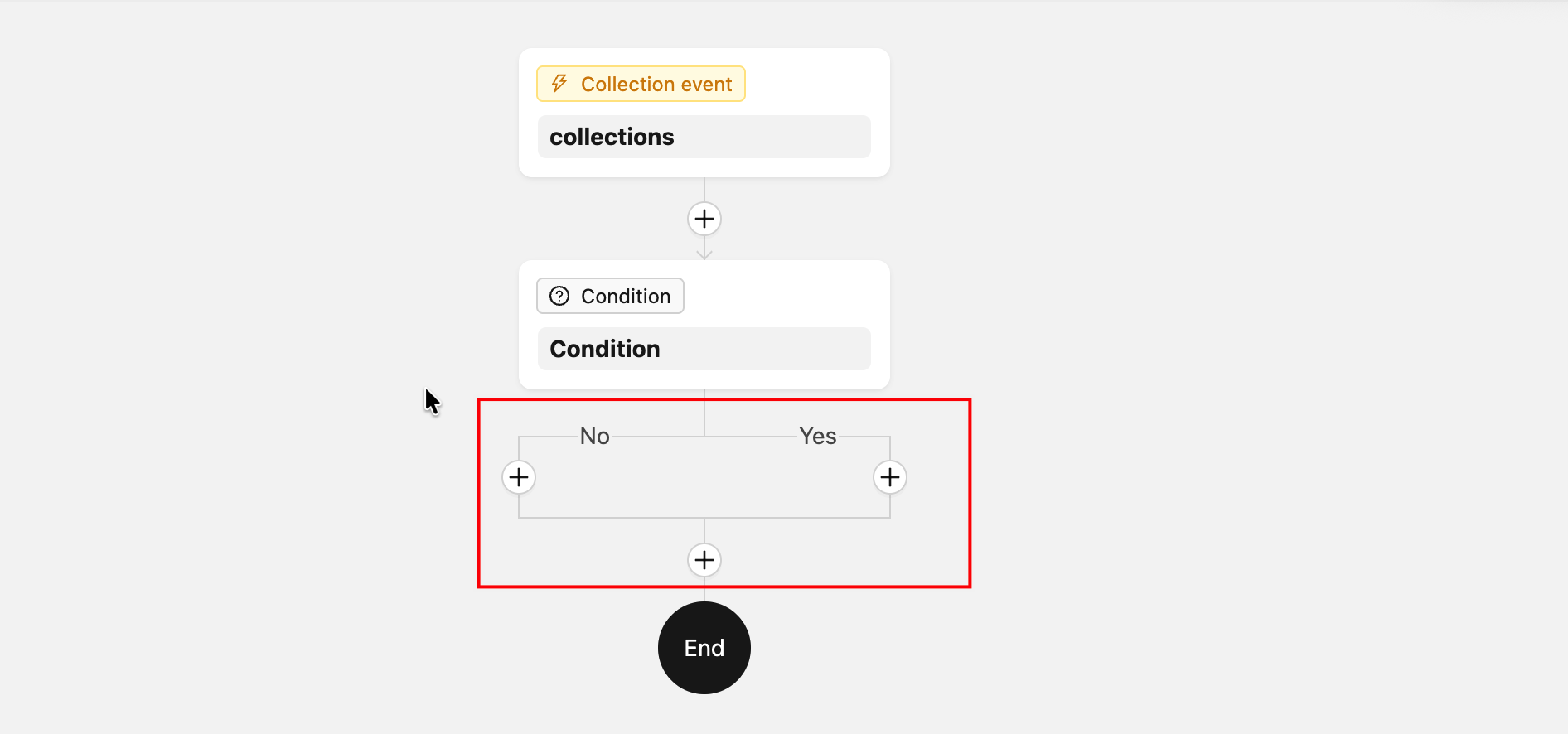
Wenn ein Loader auf einen benannten Export (statt den Standard-Export) in einer Datei verweisen soll, verwenden Sie .then() zum Remapping:
Knoten registrieren
Registrieren Sie den Knotentyp beim Workflow-Plugin innerhalb des Erweiterungs-Plugins:
Die clientseitig registrierte Knotentyp-Kennung muss mit der serverseitigen übereinstimmen, da es sonst zu Fehlern kommt.
Knotenergebnisse als Variablen bereitstellen
Sie werden die useVariables-Methode im obigen Beispiel bemerken. Wenn Sie das Ergebnis eines Knotens (den result-Teil) als Variable für nachfolgende Knoten verwenden möchten, müssen Sie diese Methode in der abgeleiteten Anweisungsklasse implementieren und ein Objekt zurückgeben, das dem Typ VariableOption entspricht. Dieses Objekt dient als strukturelle Beschreibung des Ausführungsergebnisses des Knotens und stellt eine Variablennamen-Zuordnung zur Auswahl und Verwendung in nachfolgenden Knoten bereit.
Der Typ VariableOption ist wie folgt definiert:
Der Kern ist die value-Eigenschaft, die den segmentierten Pfadwert des Variablennamens darstellt. label wird zur Anzeige in der Benutzeroberfläche verwendet, und children dient zur Darstellung einer mehrstufigen Variablenstruktur, die zum Einsatz kommt, wenn das Ergebnis des Knotens ein tief verschachteltes Objekt ist.
Eine verwendbare Variable wird intern im System als Pfad-Template-String dargestellt, der durch . getrennt ist, zum Beispiel {{$jobsMapByNodeKey.2dw92cdf.abc}}. Dabei repräsentiert $jobsMapByNodeKey die Ergebnismenge aller Knoten (intern definiert, keine weitere Bearbeitung erforderlich), 2dw92cdf ist der key des Knotens und abc ist eine benutzerdefinierte Eigenschaft im Ergebnisobjekt des Knotens.
Da das Ergebnis eines Knotens auch ein einfacher Wert sein kann, muss bei der Bereitstellung von Knotenvariablen die erste Ebene zwingend die Beschreibung des Knotens selbst sein:
Das heißt, die erste Ebene besteht aus dem key und dem Titel des Knotens. Zum Beispiel sind bei der Verwendung des Ergebnisses des Berechnungs-Knotens (siehe Code-Referenz) die Optionen in der Benutzeroberfläche wie folgt:
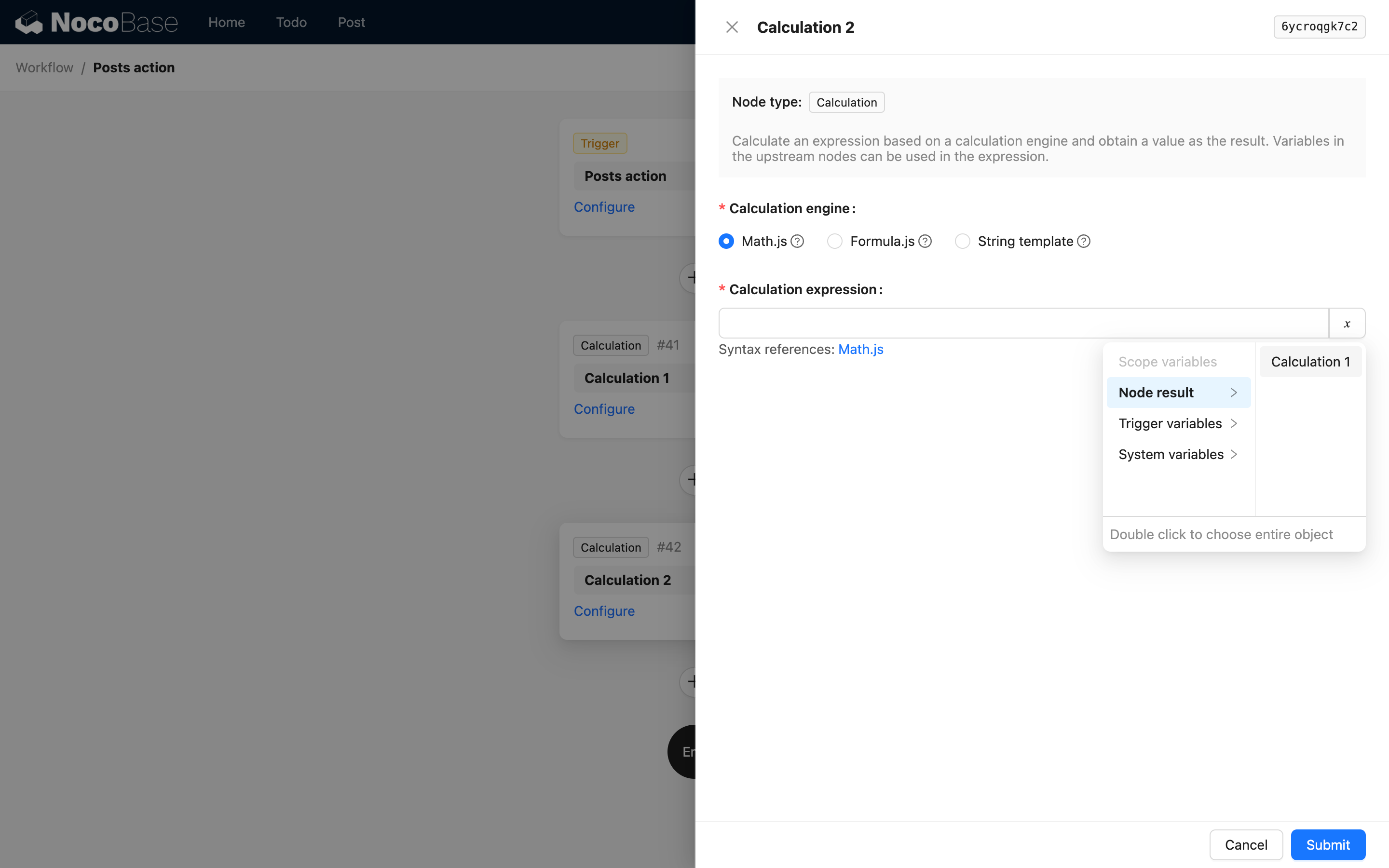
Wenn das Ergebnis des Knotens ein komplexes Objekt ist, können Sie children verwenden, um verschachtelte Eigenschaften weiter zu beschreiben. Beispielsweise könnte eine benutzerdefinierte Anweisung die folgenden JSON-Daten zurückgeben:
Dann können Sie es über die useVariables-Methode wie folgt zurückgeben:
Auf diese Weise können Sie in nachfolgenden Knoten die folgende Benutzeroberfläche verwenden, um Variablen daraus auszuwählen:
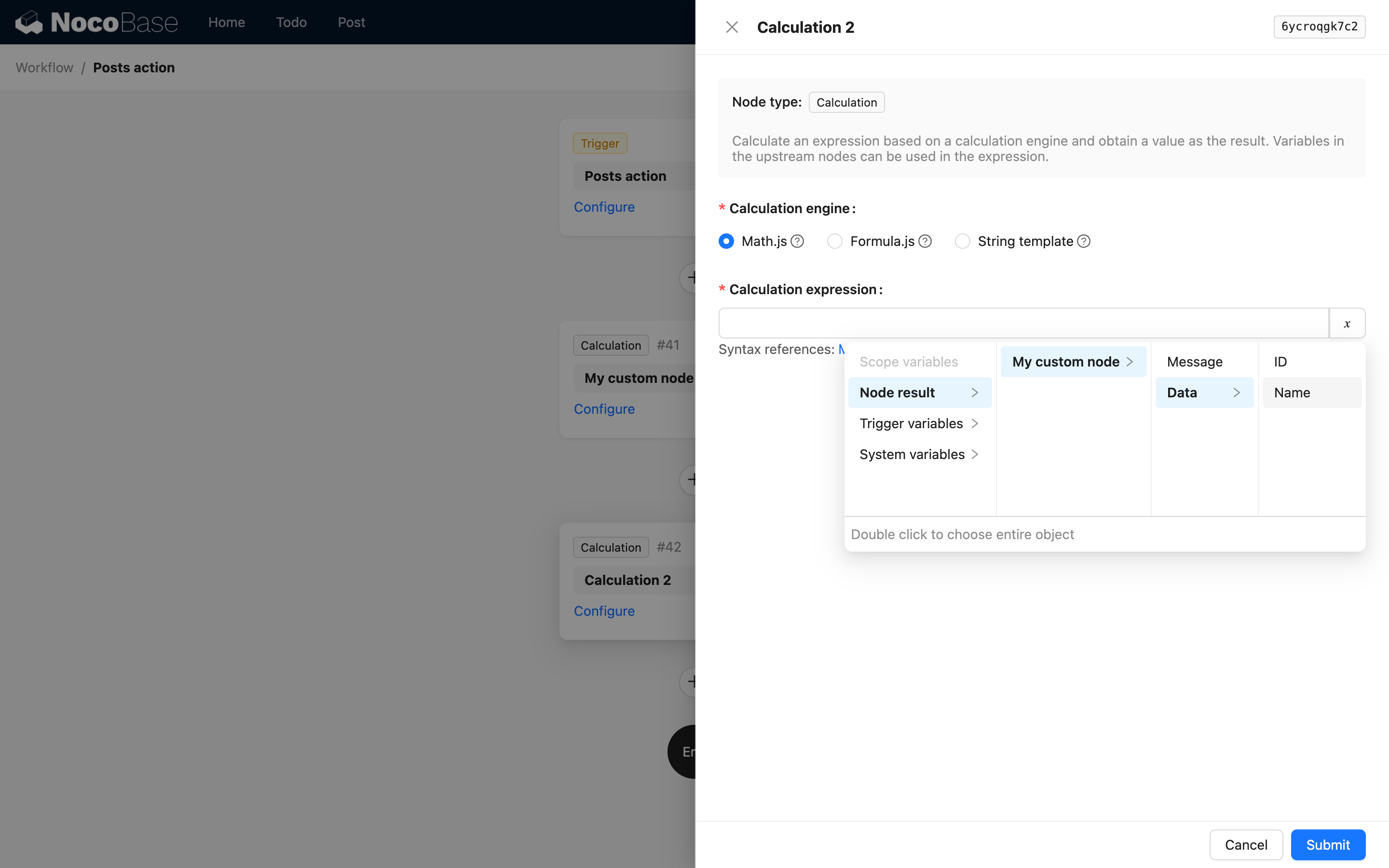
Wenn eine Struktur im Ergebnis ein Array von tief verschachtelten Objekten ist, können Sie ebenfalls children verwenden, um den Pfad zu beschreiben, dürfen aber keine Array-Indizes angeben. Dies liegt daran, dass bei der Variablenverarbeitung in NocoBase-Workflows die Pfadbeschreibung für ein Array von Objekten bei der Verwendung automatisch zu einem Array von tiefen Werten abgeflacht wird und Sie nicht über einen Index auf einen bestimmten Wert zugreifen können.
Knotenverfügbarkeit
Standardmäßig kann jeder Knoten einem Workflow hinzugefügt werden. In einigen Fällen ist ein Knoten jedoch in bestimmten Workflow-Typen oder Verzweigungen nicht anwendbar. In solchen Situationen können Sie die Verfügbarkeit des Knotens über isAvailable konfigurieren:
Die Methode isAvailable gibt true zurück, wenn der Knoten verfügbar ist, und false, wenn er nicht verfügbar ist. Der ctx-Parameter enthält die Kontextinformationen des aktuellen Knotens, anhand derer dessen Verfügbarkeit beurteilt werden kann.
Wenn keine besonderen Anforderungen bestehen, müssen Sie die isAvailable-Methode nicht implementieren, da Knoten standardmäßig verfügbar sind. Das häufigste Szenario, das eine Konfiguration erfordert, ist, wenn ein Knoten eine zeitaufwändige Operation sein könnte und nicht für die Ausführung in einem synchronen Workflow geeignet ist. Sie können die isAvailable-Methode verwenden, um seine Nutzung einzuschränken. Zum Beispiel:
Weitere Informationen
Ein vollständiges Praxisbeispiel finden Sie unter: CalculationInstruction-Quellcode
Die Definitionen der verschiedenen Parameter zur Definition von Knotentypen finden Sie im Abschnitt Workflow-API-Referenz.
Wenn Sie zuvor den Legacy-Client-Code (v1) verwendet haben und zur neuen v2-Version migrieren möchten, lesen Sie den Migrationsleitfaden von v1 zu v2.