

ノードタイプの拡張
ノードのタイプは、本質的に操作の指示そのものです。異なる指示は、ワークフロー内で実行される異なる操作を表します。
トリガーと同様に、ノードタイプの拡張もサーバーサイドとクライアントサイドの2つの部分に分かれます。サーバーサイドでは登録された指示のロジックを実装する必要があり、クライアントサイドではその指示が配置されるノードの関連パラメーターのインターフェース設定を提供する必要があります。
サーバーサイド
最もシンプルなノード指示
指示の核となる内容は関数です。つまり、指示クラス内の run メソッドは、指示のロジックを実行するために必ず実装する必要があります。関数内では、データベース操作、ファイル操作、サードパーテ��ィAPIの呼び出しなど、必要なあらゆる操作を実行できます。
すべての指示は Instruction 基底クラスから派生させる必要があります。最もシンプルな指示は、run 関数を1つ実装するだけで済みます。
そして、この指示をワークフロー プラグインに登録します。
指示の戻りオブジェクトにあるステータス値(status)は必須項目であり、JOB_STATUS 定数内の値である必要があります。この値は、ワークフローにおけるこのノードのその後の処理の流れを決定します。通常は JOB_STATUS.RESOVLED を使用します。これは、ノードが正常に実行を完了し、後続のノードの実行が継続されることを意味します。もし事前に保存する必要がある結果値がある場合は、processor.saveJob メソッドを呼び出し、その戻りオブジェクトを返すこともできます。実行者はこのオブジェクトに基づいて実行結果のレコードを生成します。
ノードの結果値
特定の実行結果がある場合、特に後続のノードで使用するためのデータを準備する場合は、result プロパティを介して返し、ノードのジョブオブジェクトに保存できます。
node.config はノードの設定項目で、必要な任意の値を設定できます。これは、データベース内の対応するノードレコードに JSON 型フィールドとして保存されます。
指示のエラー処理
実行中に例外が発生する可能性がある場合は、事前にキャッチして失敗ステータスを返すことができます。
予測可能な例外をキャッチしない場合、ワークフローエンジンが自動的にキャッチし、エラー状態を返します。これにより、捕捉されない例外によるプログラムのクラッシュを防ぎます。
非同期ノード
ノードがワークフローを継続する前に外部操作の完了を待つ必要がある場合(HTTPリクエスト、サードパーティの決済コールバック、その他の時間のかかる操作や即座に結果が返されない操作など)、まず JOB_STATUS.PENDING ステータスでタスクを保存して現在の実行を一時停止し、操作完了後に resume を通じて再開する必要があります。一時停止ロジックを使用する指示は必ず resume メソッドを実装する必要があります。そうしないと、ワークフローを再開できません。
推奨される実装��パターンは以下の通りです。
注意すべき重要な点がいくつかあります。
なぜ保留中のタスクオブジェクトを返す代わりに processor.exit() を明示的に呼び出すのか?
return { status: PENDING } は run 関数をすぐに終了させるため、その後のコードを実行することが不可能になります。await processor.exit() を呼び出すと、トランザクションをコミットしてデータベースコンテキストを終了するだけで、関数自体は引き続き実行されます。これにより、同じ関数本体内で時間のかかる操作を await し、完了時に resume を呼び出すことができます。exit() をスキップして返す前に長い操作を直接 await すると、データベーストランザクションを長��時間オープンにしてロック競合を引き起こすだけでなく、操作完了後のトランザクションコミット時まであタスクレコードが永続化されません。
なぜ saveJob が返したオブジェクトを使用せずにタスクを再クエリするのか?
saveJob が返すオブジェクトは、元のトランザクションに紐付けられたインメモリモデルインスタンスです。processor.exit() が呼び出された後、そのトランザクションはコミットされてクローズされています。このインスタンスを直接変更して resume を呼び出すと、ORMの状態異常(古いトランザクション参照、状態の不整合など)が発生します。id によってデータベースから再クエリすることで、どのトランザクションにも紐付けられていないクリーンなインスタンスを確保できます。
なぜ run 関数は何も返さない(void)のか?
processor.exit() はすでに手動で呼び出されています。エグゼキューターが void を受け取ると、exit(true) を呼び出して冗長な処理なく即座に終了します。この時点で IJob を返すと、エグゼキューターが再度保存とコミットを試みてエラーが発生します。詳細は run/resume の戻り値の型セクションを参照してください。
外部コールバックが必要なシナリオの場合(例:Webhookで通知される決済結果)、同じアプローチが適用されます。コールバックを登録する前に processor.exit() を呼び出して、外部システムがコールバックする前にタスクレコードがデータベースに存在することを確認します�。コールバック内では、id でタスクを再クエリし、this.workflow.resume(job) を呼び出します。
完全な実際の例については、RequestInstruction.ts(HTTPリクエストノード。非同期ワークフローブランチでこのパターンを使用)を参照してください。
ノードの結果ステータス
ノードの実行ステータスは、ワークフロー全体の成功または失敗に影響します。通常、分岐がない場合、あるノードの失敗はワークフロー全体の失敗に直結します。最も一般的なシナリオは、ノードが正常に実行された場合、ノードテーブルの次のノードに進み、後続のノードがなくなるまで、ワークフロー全体の実行が成功ステータスで完了することです。
実行中にいずれかのノードが実行失敗ステータスを返した場合、エンジンは以下の2つの状況に応じて異なる処理を行います。
-
失敗ステータスを返したノードがメインワークフロー内にあり、かつ上流ノードによって開始されたどの分岐ワークフロー内にもない場合、メインワークフロー全体が失敗と判断され、ワークフローは終了します。
-
失敗ステータスを返したノードが特定の分岐ワークフロー内にある場合、ワークフローの次のステータスを判断する責任は、その分岐を開始したノードに委ねられます。そのノードの内部ロジックが後続のワークフローのステータスを決定し、この決定はメインワークフローまで再帰的に伝播します。
最終的に、ワークフロー全体の次のステータスはメインワークフローのノードで決定されます。もしメインワークフローのノードで失敗が返された場合、ワークフロー全体は失敗ステータスで終了します。
いずれかのノードが実行後に「一時停止」ステータスを返した場合、実行ワークフロー全体は一時的に中断され、保留状態になります。これは、対応するノードによって定義されたイベントがトリガーされ、ワークフローの実行が再開されるのを待ちます。例えば、手動ノードは、このノードに到達すると「一時停止」ステータスで停止し、手動での介入を待ち、承認するかどうかを決定します。手動で入力されたステータスが承認であれば、後続のワークフローノードが続行されます。そうでなければ、前述の失敗ロジックに従って処理されます。
その他の指示の戻りステータスについては、ワークフローAPIリファレンスセクションを参照してください。
run/resume の戻り値の型と実行器の動作
run および resume メソッドの完全な戻り値型定義は以下の通りです。
エグゼキューター(Processor)が指示を呼び出した後、戻り値の型に基づいて異なる処理ロジックを実行します。3つのケースがあります。
1. タスクオブジェクト IJob を返す
これが最も一般的なケースです。必須の status フィールドとオプションの result フィールドを含むオブジェクトを返します。エグゼキューターはそれをノードのタスクレコードとして保存し、status 値に基づいてその後のフローを決定します。
JOB_STATUS.RESOLVED: ノードが正常に実行�され、次のノードがある場合は継続し、なければワークフローが終了するJOB_STATUS.PENDING: ノードが一時停止状態に入り、現在の実行コンテキストが停止して外部イベントがresumeをトリガーするのを待つ- その他の失敗ステータス(
FAILED、ERRORなど): 分岐の親ノードに伝播するか、ワークフロー全体を直接終了する
このパスは完全なトランザクションコミットパスです — エグゼキューターはタスクレコードを保存し、データベースに書き込み、トランザクションをコミットします。
例: ConditionInstruction.ts(分岐がない場合は job オブジェクトを直接返す。分岐がある場合の void ケースについては以下を参照)
2. null を返す
null が返された場合、エグゼキューターは processor.exit()(引数なし)を呼び出します。その効果は、現在保留中のタスクをデータベースにフラッシュしてトランザクションをコミットするが、全体の実行ステータスは更新しないというものです。
この使用法は、分岐制御ノードの resume メソッドでよく見られます。分岐が完了し、親ノードのタスクステータスを更新して保存する必要がある場合(例:「分岐Nが完了した」を記録する)、他の分岐はまだ実行中で、全体の実行は残りの分岐を待つために STARTED ステータスのまま維持する必要があります — null を返すことで、全体の実行ステータスに影響を与えることなく、現在の resume コンテキストを終了します。
- 行 117: 並列ノードがすでに早期完了している(resolved/rejected); 後続の分岐 resume を無視して直接
nullを返す - 行 135: 一部の分岐がまだ未完了(
PENDING); 現在の進行状況を保存してnullを返し、他の分岐を待ち続ける
3. void を返す(return なし、つまり暗黙的な undefined)
void が返された場合(関数に明示的な return 文がない、または実行パスが戻り値なしで終了する)、エグゼキューターは processor.exit(true) を呼び出します。その効果は、データベース操作を一切行わず即座に戻るというものです。
このパターンは専ら指示が実行スケジューリングを��引き継いだシナリオのためのものです。指示が processor.run() を通じてサブワークフローを手動で開始し、サブワークフローの実行チェーンが完了時にデータベース書き込みとトランザクションコミットを処理します。エグゼキューターは再度処理すべきではありません。
典型的な例:
- ConditionInstruction.ts#L67: 分岐が存在する場合、
processor.run(branchNode, savedJob)を手動で呼び出し、関数が終了して暗黙的にvoidを返す - ParallelInstruction.ts#L108: すべての分岐を反復して各々に
processor.run(branch, job)を呼び出し、関数が終了して暗黙的にvoidを返す
:::warn{title=ヒント}
void を返す前に processor.saveJob() が呼び出されていた場合、それらのタスクレコードは現在のエグゼキューターによってデータベースに書き込まれません。それらはエグゼキューターのタスクリスト(メモリ内)に一時的に保存され、processor.run() によって開始されたサブ実行が完了したときにトリガーされる exit() によってデータベースにフラッシュされます。したがって、このパターンを使用する場合は、これらのレコードを永続化するために正常に完了するサブ実行パスが存在することを確認する必要があります。分岐ワー��クフローのスケジューリングにはある程度の複雑さがあります。慎重な設計と徹底的なテストが必要です。
:::
3つの戻り値の比較まとめ:
詳細
ノードタイプを定義するための各パラメーターの定義については、ワークフローAPIリファレンスセクションを参照してください。
クライアントサイド
トリガーと同様に、指示(ノードタイプ)の設定フォームはフロントエンドで実装する必要があります。
最もシンプルなノード指示
すべての指示は Instruction 基底クラスから派生させる必要があります。関連するプロパティとメソッドは、ノードの設定と使用のために用いられます。
例えば、上記でサーバーサイドに定義したランダムな数字文字列タイプ(randomString)のノードに対して設定インターフェースを提供する必要がある場合、その設定項目の一つである digit は、ランダムな数字の桁数を表します。設定フォームでは、ユーザー入力を受け取るために数値入力ボックスを使用します。
クライアントサイドで登録するノードタイプの識別子は、サーバーサイドのものと一致している必要があります。そうしないとエラーが発生します。
ノードの結果を変数として提供する
上記の例にある useVariables メソッドに注目してください。ノードの結果(result 部分)を後続のノードで変数として使用する必要がある場合、継承する指示クラスでこのメソッドを実装し、VariableOption タイプに準拠したオブジェクトを返す必要があります。このオブジェクトは、ノードの実行結果の構造を記述するものとして機能し、後続のノードで選択して使用できる��ように、変数名のマッピングを提供します。
VariableOption の型定義は以下の通りです。
核となるのは value プロパティです。これは変数名のセグメント化されたパス値を表します。label はインターフェース上に表示するために使用され、children は多階層の変数構造を表すために使用されます。ノードの結果が深い階層のオブジェクトである場合に使用されます�。
使用可能な変数は、システム内部では . で区切られたパスのテンプレート文字列として表現されます。例えば {{jobsMapByNodeKey.2dw92cdf.abc}} のようになります。ここで $jobsMapByNodeKey はすべてのノードの結果セットを表し(内部で定義済みのため、処理は不要です)、2dw92cdf はノードの key です。abc はノードの結果オブジェクト内のカスタムプロパティです。
また、ノードの結果は単純な値である可能性もあるため、ノード変数を提供する際には、最初の階層はノード自体の記述である必要があります。
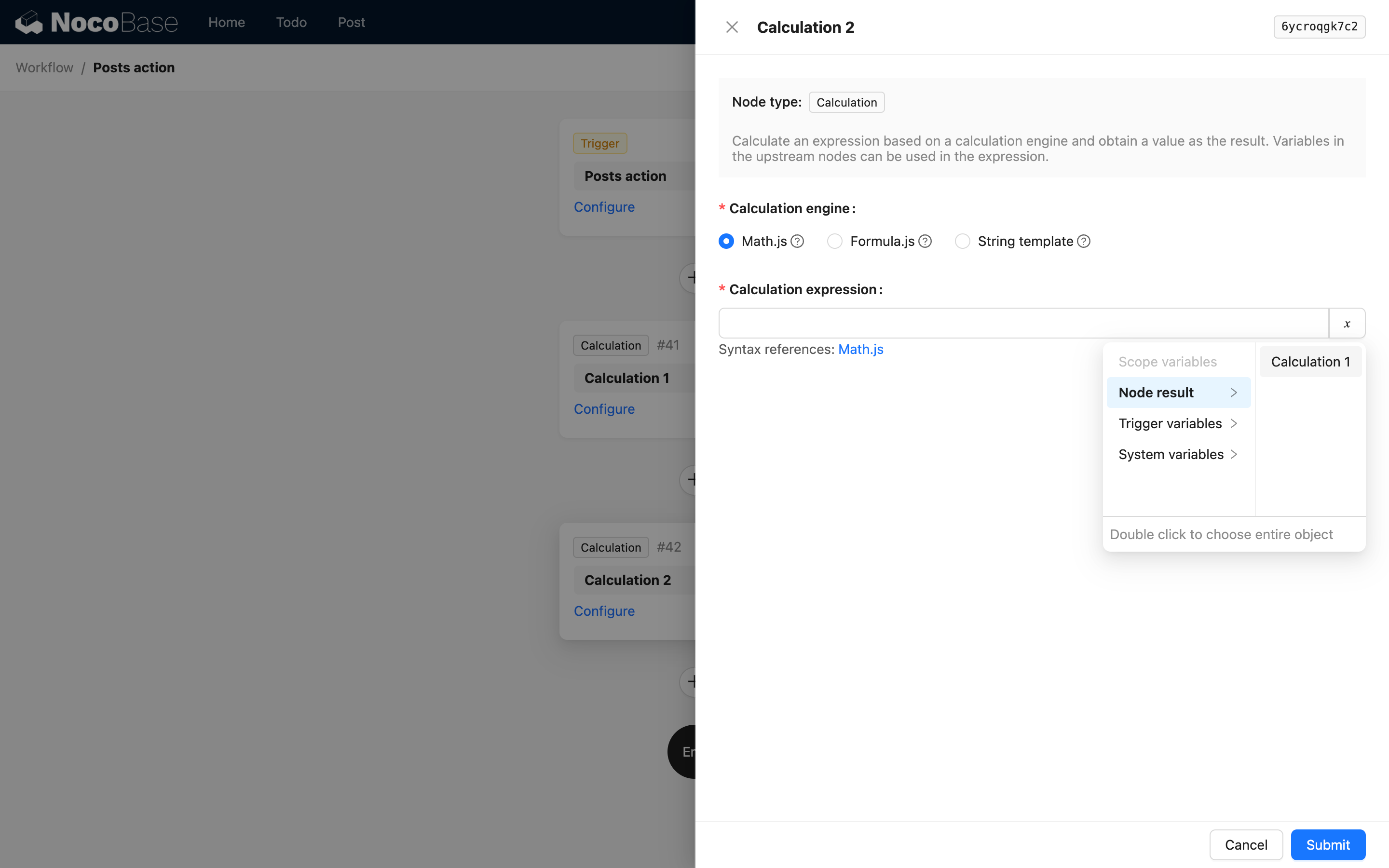
つまり、最初の階層はノードの key とタイトルです。例えば、計算ノードのコード参照では、計算ノードの結果を使用する際のインターフェースオプションは以下のようになります。
ノードの結果が複雑なオブジェクトである場合、children を使用してさらに深い階層のプロパティを記述でき��ます。例えば、カスタム指示が以下のJSONデータを返す場合です。
その場合、以下の useVariables メソッドを介して返すことができます。
これにより、後続のノードで以下のインターフェースを使用してその中の変数を選択できるようになります。
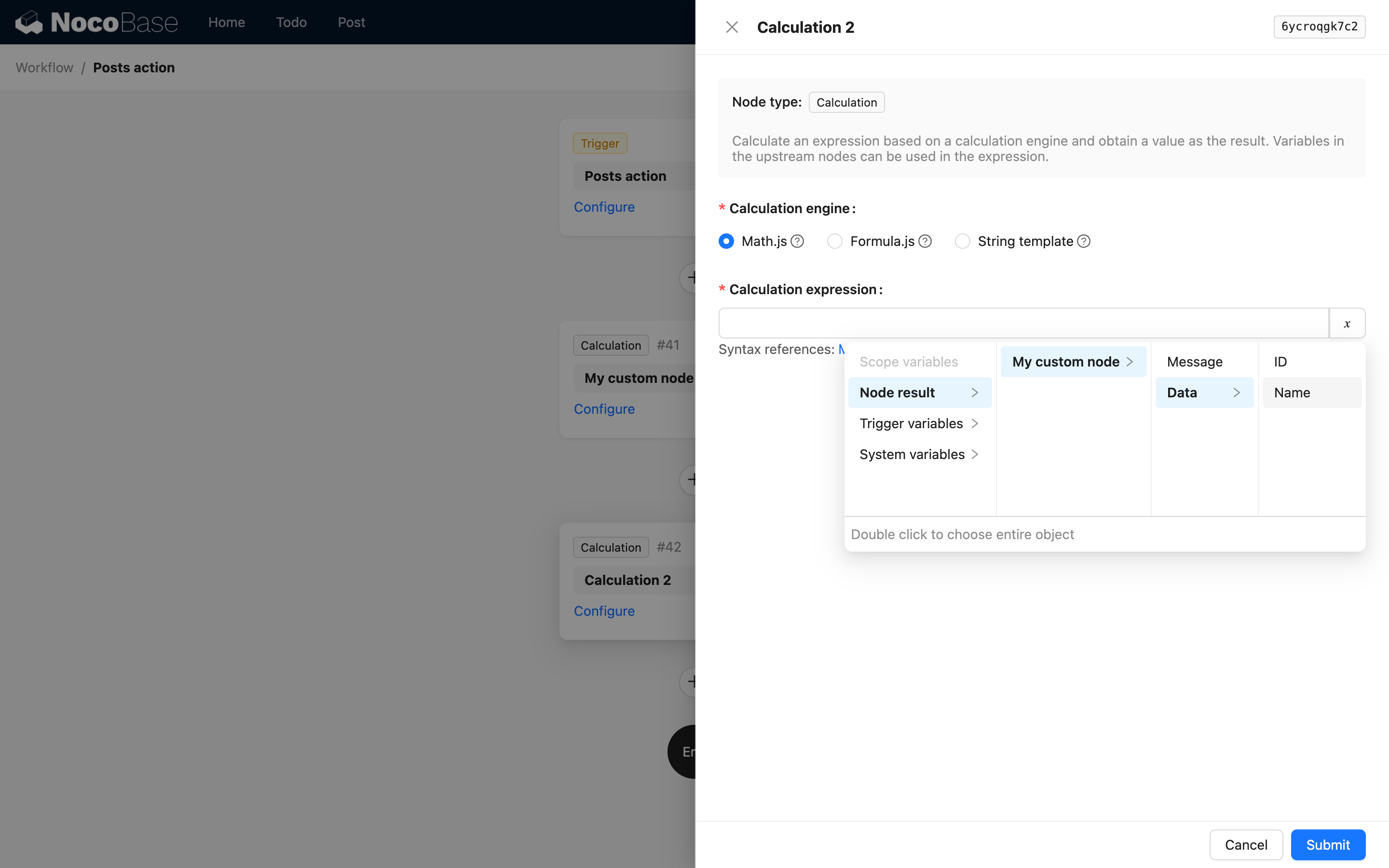
結果内の構造が深い階層のオブジェクト配列である場合も、同様に children を使用してパスを記述できますが、配列のインデックスを含めることはできません。これは、NocoBaseのワークフローにおける変数処理では、オブジェクト配列の変数パス記述は使用時に自動的に深い階層の値の配列にフラット化され、インデックスを介して特定の値にアクセスできないためです。
ノードの可用性
デフォルトでは、ワークフローには任意のノードを追加できます。しかし、特定の状況では、ノードが特定のタイプのワークフローや分岐内で適用できない場合があります。この場合、isAvailable を使用してノードの可用性を設定できます。
isAvailable メソッドが true を返す場合、ノードは利用可能であることを示し、false の場合は利用不可であることを示します。ctx パラメーターには、現在のノードのコンテキスト情報が含まれており、これらの情報に基づいてノードが利用可能かどうかを判断できます。
特別な要件がない場合、isAvailable メソッドを実装する必要はありません。ノードはデフォルトで利用可能です。最も一般的な設定が必要なシナリオは、ノードが時間のかかる操作である可能性があり、同期ワークフローでの実行には適さない場合です。isAvailable メソッドを使用してノードの使用を制限できます。例えば、
詳細
ノードタイプを定義するための各パラメーターの定義については、ワークフローAPIリファレンスセクションを参照してくださ��い。