

JSON 変数マッピング
Workflow: JSON variable mappingCommunity Edition+v1.6.0
概要
上流ノードの結果に含まれる複雑なJSON構造を、後続ノードで利用できる変数としてマッピングするために使用します。例えば、SQL操作やHTTPリクエストノードの結果は、マッピングすることで後続ノードでそのプロパティ値を使用できるようになります。
JSON計算ノードとは異なり、JSON変数マッピングノードはカスタム式をサポートしておらず、サードパーティのエンジンにも依存していません。JSON構造内のプロパティ値をマッピングするためだけに使用されますが、よりシンプルに利用できます。
ノードの作成
ワークフロー設定画面で、フロー内のプラス(「+」)ボタンをクリックして、「JSON 変数マッピング」ノードを追加します。
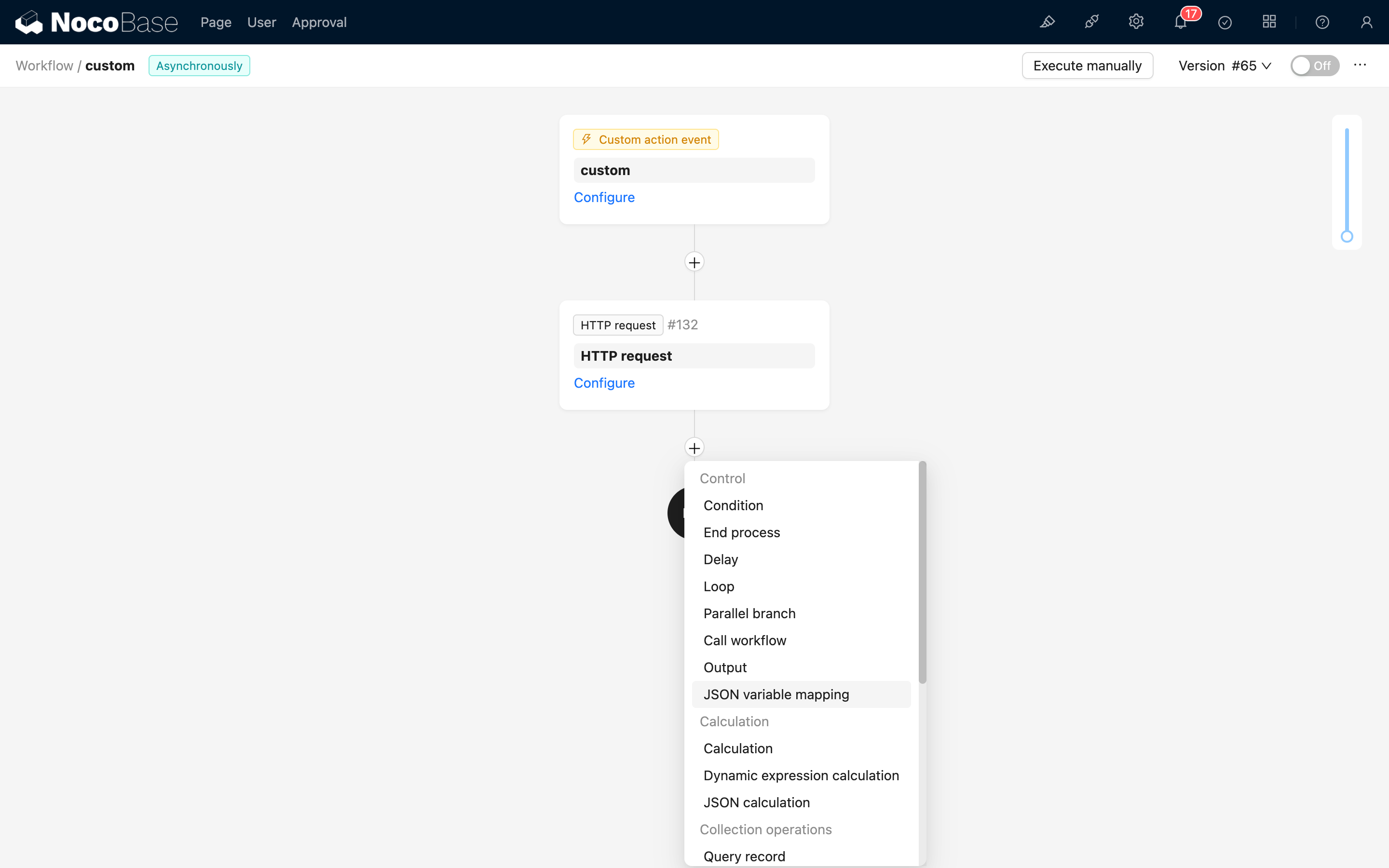
ノードの設定
データソース
データソースは、上流ノードの結果、またはプロセスコンテキスト内のデータオブジェクトのいずれかです。通常、SQLノードの結果やHTTPリクエストノードの結果のように、組み込みの構造化されていないデータオブジェクトを指します。
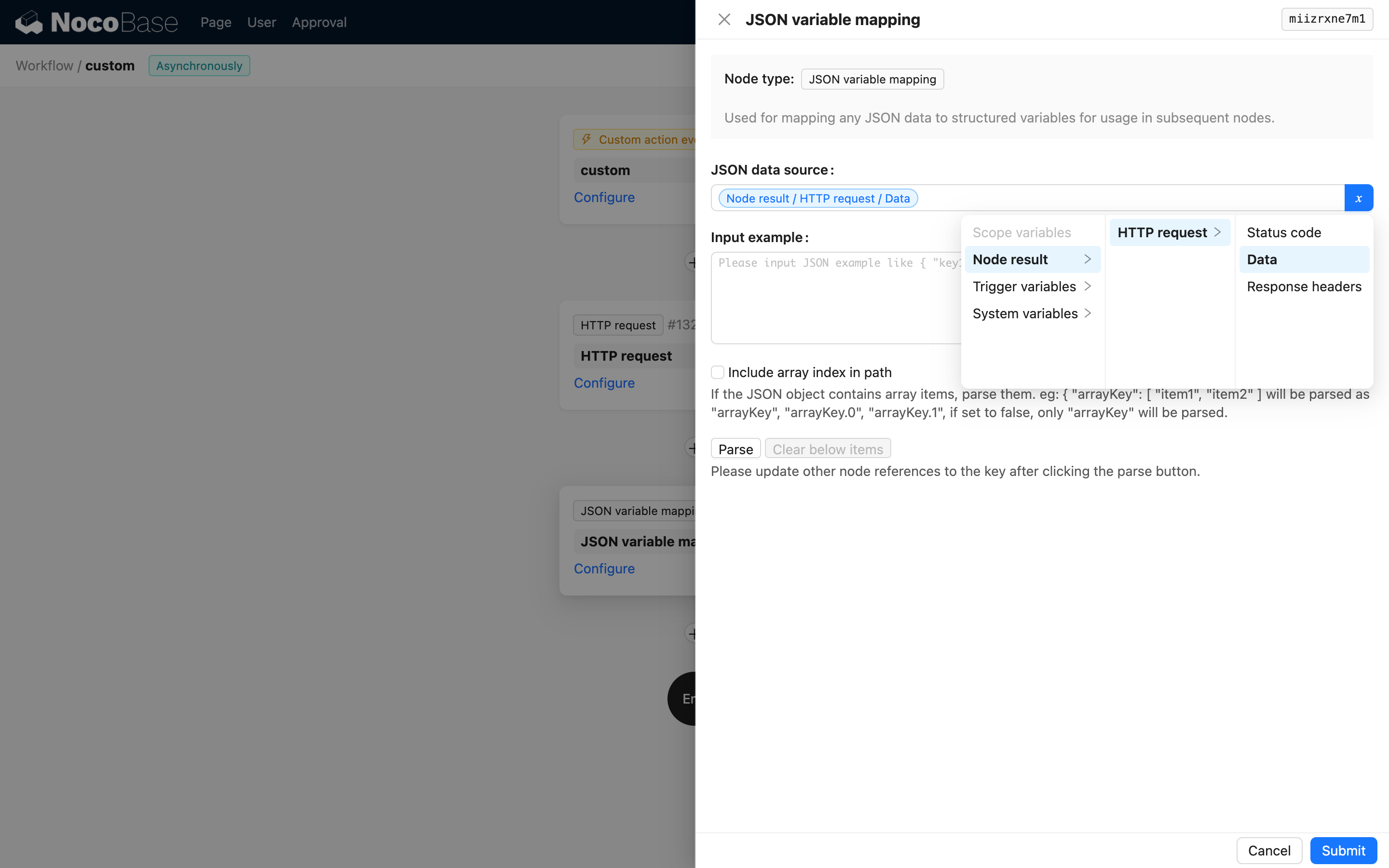
サンプルデータの入力
サンプルデータを貼り付け、解析ボタンをクリックすると、変数リストが自動的に生成されます。
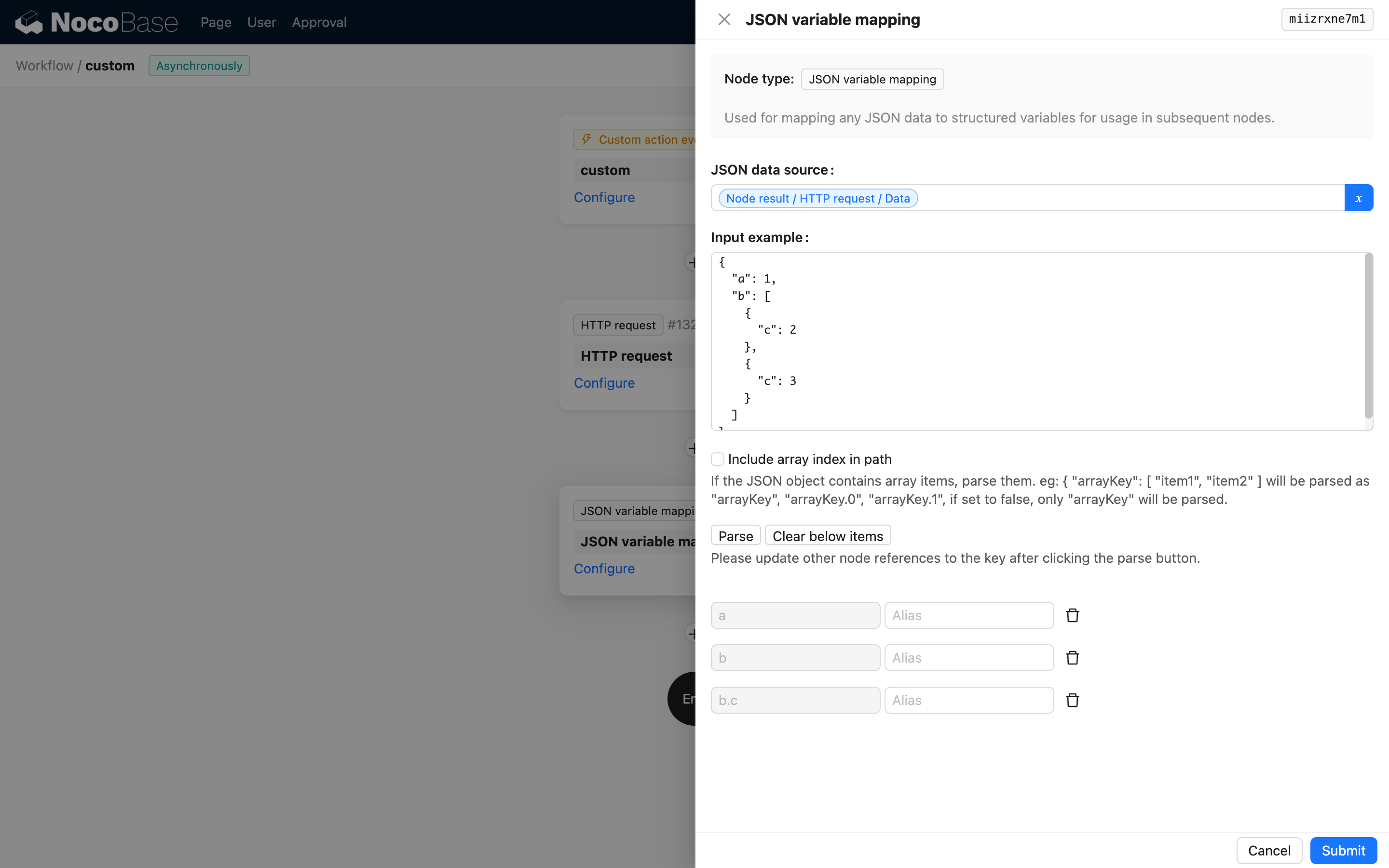
自動生成されたリストに不�要な変数がある場合は、削除ボタンをクリックして削除できます。
サンプルデータは最終的な実行結果ではなく、変数リストの生成を補助するためだけに使用されます。
パスに配列インデックスを含める
このオプションをオフにした場合、NocoBase ワークフローのデフォルトの変数処理方法に従って、配列の内容がマッピングされます。例えば、以下のサンプルを入力すると:
生成される変数では、b.c が配列 [2, 3] を表します。
このオプションをオンにした場合、変数パスに配列インデックスが含まれるようになります。例えば b.0.c や b.1.c のようになります。
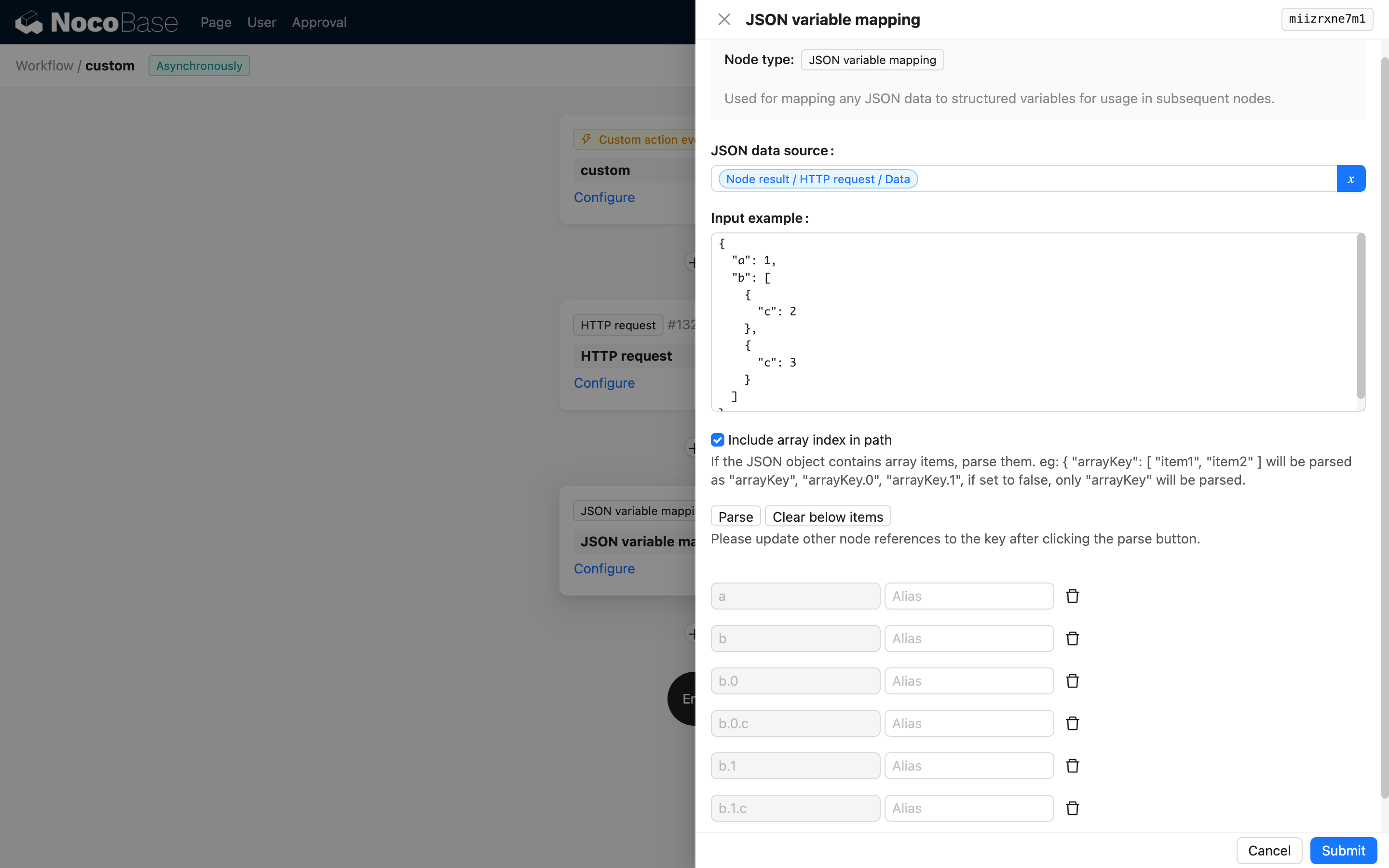
配列インデックスを含める場合、入力データ内の配列インデックスが一貫していることを確認する必要があります。そうでない場合、解析エラーが発生する可能性があります。
後続ノードでの使用
後続ノードの設定で、JSON変数マッピングノードで生成された変数を使用できます。
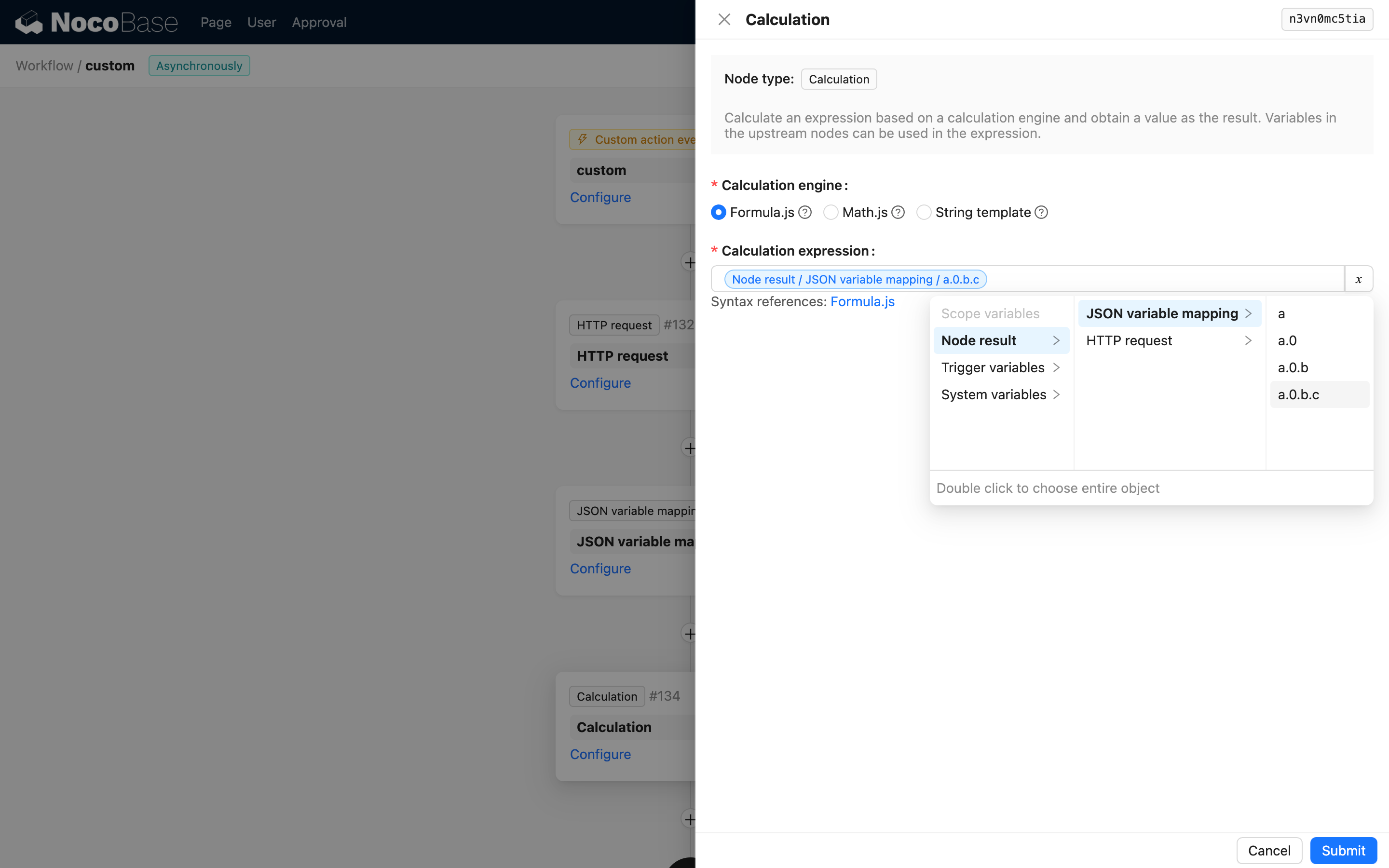
JSON構造は複雑になることがありますが、マッピング後は対応するパスの変数を選択するだけで済みます。